![[图像编辑06] plug-and-play](https://s2.loli.net/2025/03/18/Sar7yFEJDMjVqxt.jpg)
Table of Contents
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation Link to Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
From:CVPR2023
之前的文章比如p2p是对cross-attention层下手,这次是对self-attention下手了
预备知识再复习 Link to 预备知识再复习
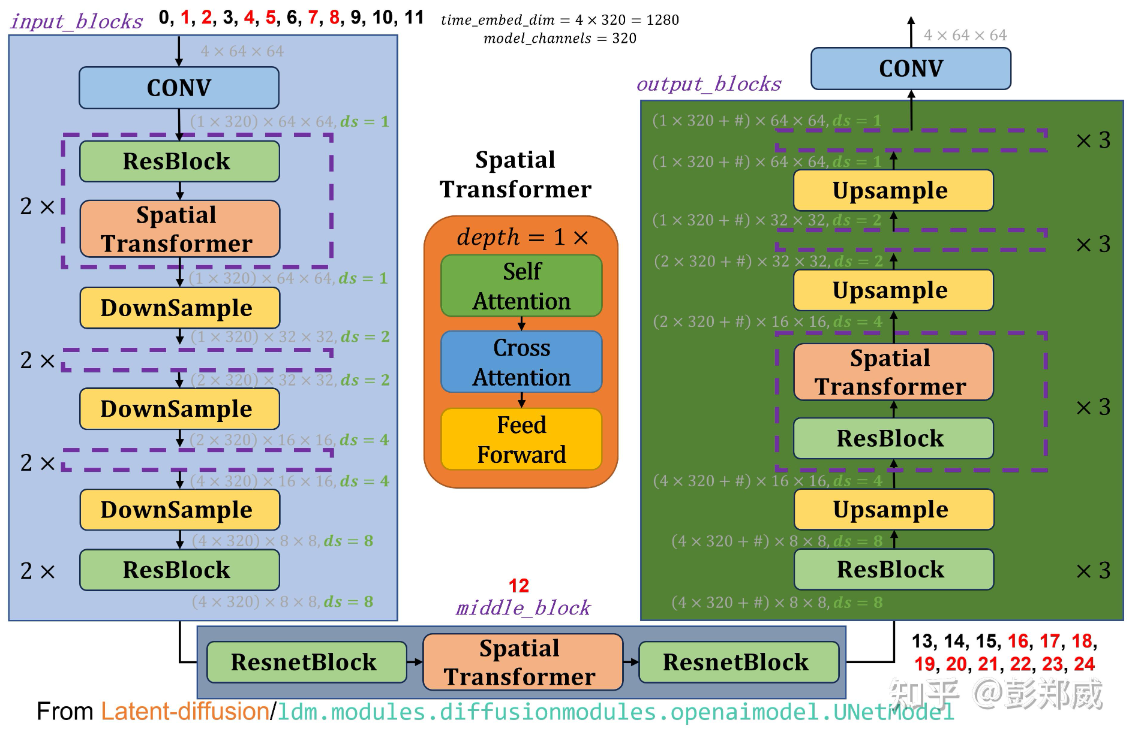
Stable Diffusion中的U-Net架构:紫色框表示相同内容的模块
Stable Diffusion 的 UNet 和 Attention - 知乎
Movition Link to Movition
作者提出经验性的2个观点:
Spatial features extracted from intermediate decoder layers encode localized semantic information and are less affected by appearance information.
从中间解码器层提取的空间特征编码了局部语义信息,受外观信息的影响较小。
The self-attention, representing the affinities between the spatial features, allows to retain fine layout and shape details.
Self-attention可以represent空间特征之间的匹配度,能够保留细粒度布局和形状信息。
Method Link to Method
下面是论文架构,没什么用
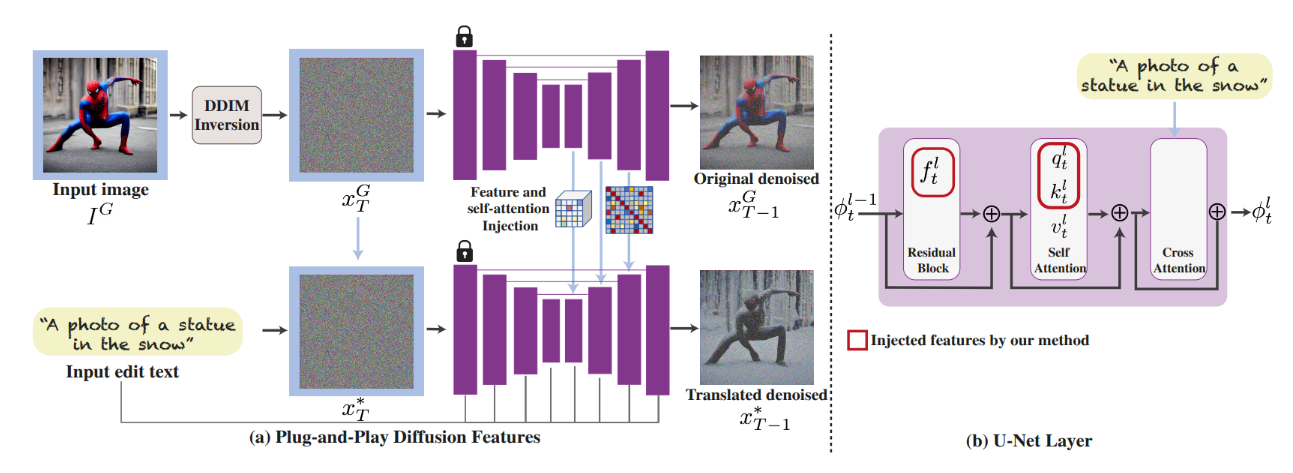

对照算法图:首先是把原来的真实图片作为引导图片做DDIM-inversion,得到的就是原图的初始噪声分布,该噪声分布也将作为马上编辑的初始噪声图。作者设定了2个阈值和,在一定的步数,使用原图在第四层ResBlock得到的特征和Self-attention得到的特征图直接替换使用编辑的文本得到的和,其中这里的。
这样做的原因是作者做了一些实验观察得到的,如下图

图的名称为特征消融与注意力注入
(a) 从引导图像(左侧)提取的特征被注入到转换图像的生成过程中(由给定的文本提示引导)。虽然中间层(第4层)的特征展示了局部语义信息,但单独注入这些特征不足以保持引导结构。引入更深层(且更高分辨率)的特征有助于更好的结构保持,但会导致引导图像的外观泄漏到生成图像中(第4-11层)。
(b) 仅在第4层注入特征,并在更高分辨率层注入自注意力图,可以缓解这一问题。
(c) 仅注入自注意力图会限制特征之间的关联性,但引导特征与生成特征之间缺乏语义关联,导致结构对齐错误。我们最终配置的结果用橙色高亮显示。
参考 Link to 参考
[CVPR 2023] Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation - 知乎
[图像编辑06] plug-and-play
© JuneSnow | CC BY-SA 4.0