
从Group Diffusion Transformer到Incontext LoRA
Table of Contents
从Group Diffusion Transformer到InContext LoRA Link to 从Group Diffusion Transformer到InContext LoRA
一、Group Diffusion Transformer Link to 一、Group Diffusion Transformer
Motivation Link to Motivation
在NLP领域,大语言模型具有任务无关的能力。
而图像领域,图像转变、风格迁移和角色定制等视觉生成任务仍然严重依赖于有监督的、特定任务的数据集,以及训练特定的模块比如LoRA,adapter,controlnet,编码器等。
这种对专门数据和架构的依赖,给可扩展性和泛化性带来了严峻的挑战。
- 首先,未能利用互联网上大量可用的弱监督数据,从而限制了可扩展性;且创建和管理特定任务的数据集需要大量的人工劳动。
- 其次,它限制了模型对未见过数据的适应性。
- 最后,跨任务适应性不足,尤其是在组合控制方面,即难以同时隐式地管理多个任务。
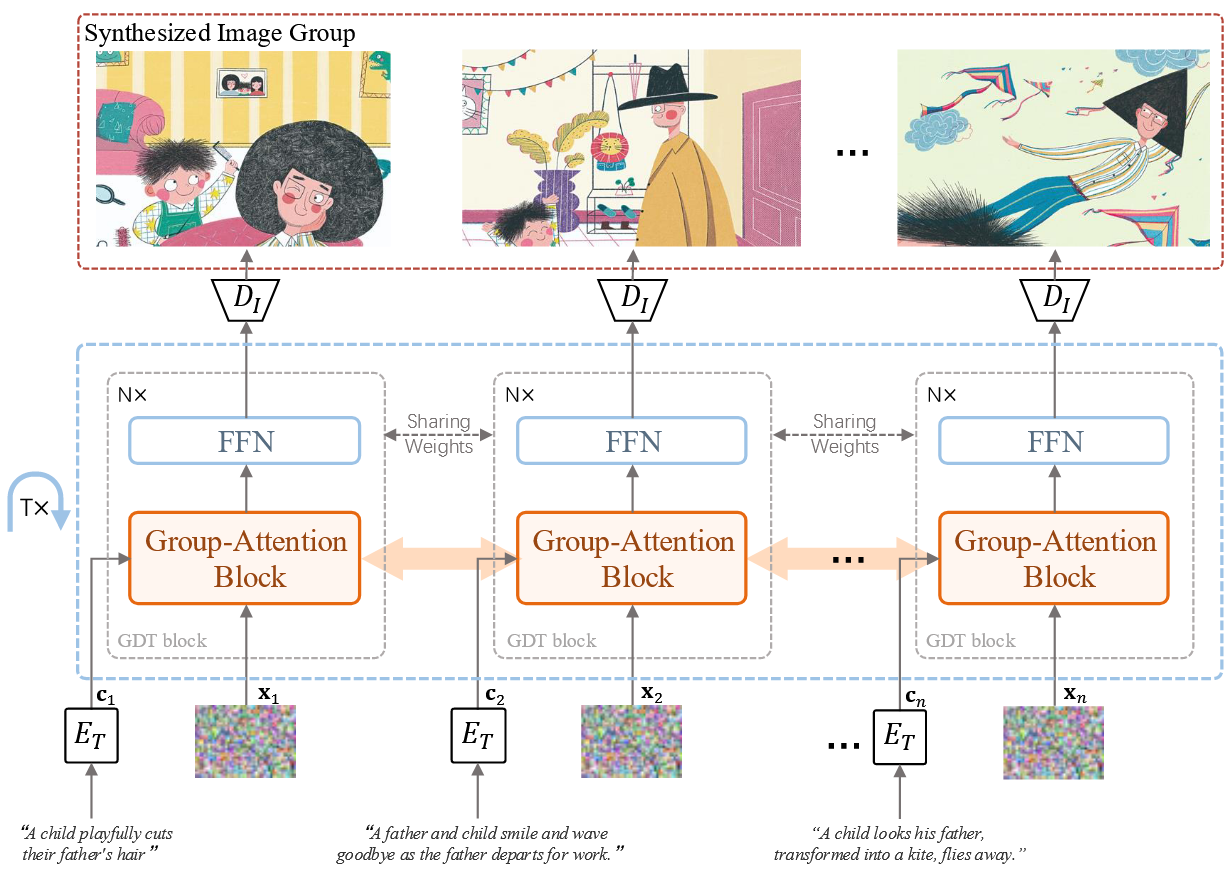
我们提出Group Diffusion Transformer,将不同的视觉生成任务定义为组生成问题。GDT基于DiT,仅做微小改动。
组生成问题:目标是生成一组元素,每个元素有其对应的上下文条件。这些元素的关系由其上下文条件内的相互依赖性决定。可以选择提供的部分,要求生成的部分。这个问题举例为,比如给定连环画的前几张,再给一长段描述,模型可以自然连贯的生成剩下的很多图片吧。
当然,不止这个连环画,作者总结很多问题都是这样的通式,所以可以搞。

- 方法核心思想:在扩散模型(DiT)的自注意力(self-attention)中,把来自不同组元素的 tokens 拼接(concatenate)在一起,这样它们就能在模型各层中相互交互。
Method Link to Method
为了解决组生成问题,至关重要的是在生成过程中建立多个组元素之间的联系,使模型能够感知和利用这些元素之间的相关性。
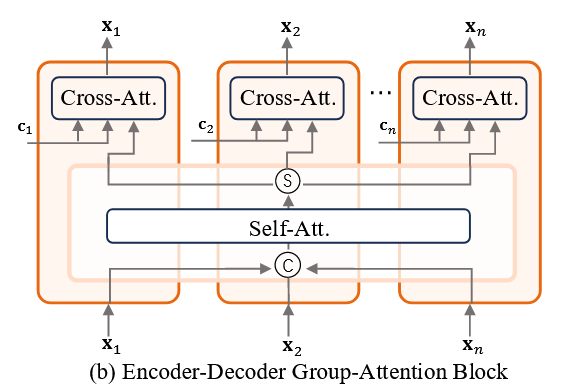
(a) Encoder–Decoder 架构 Link to
- 代表模型:PixArt。
- 原本流程:每个 transformer block 包含:
- 图像自注意力(image self-attention)
- 图文交叉注意力(cross-attention)
- 前馈网络(feed-forward network)
- 改动:
- 在自注意力中,把组内所有图片的 tokens 拼接在一起,让每个 token 都能看到组内所有其他图片的 tokens。
- 自注意力结束后,再按原来的分组方式拆开。
- 在交叉注意力阶段,每个图片 token 只与自己对应的文本描述交互。
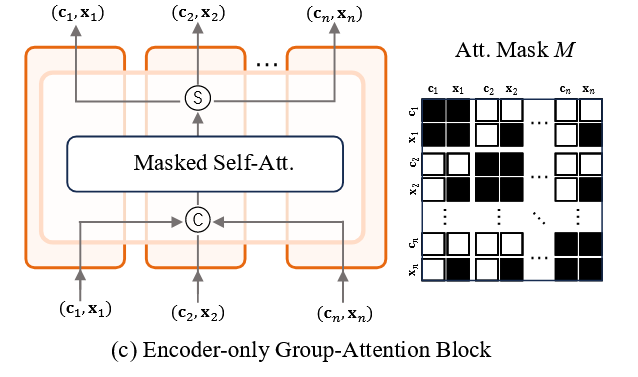
(b) Encoder–Only 架构 Link to
代表模型:Stable Diffusion 3, FLUX。
原本流程:transformer block 中有自注意力和前馈网络。
改动:
首先,把所有图片 tokens 和文本 tokens 拼接在一起。
进行带掩码的自注意力(masked self-attention):
- 图片 tokens:可以看到组内所有 token(包括图片和文本)。
- 文本 tokens(context tokens):只能看到自己的文本 token 和对应的图片 tokens。
公式:
这里 表示 token 是否能关注 token 。
InContext LoRA Link to InContext LoRA
是GDT的续作,因为还是同一个团队阿里的Tongyi Lab写的,不过论文都没中呢。
Motivation Link to Motivation
假设文本到图像的 DiTs 本身就具备上下文生成能力,只需要极少的调整即可激活。通过各种任务实验,我们定性地证明了现有的文本到图像 DiTs 无需任何调整即可有效地执行上下文生成。
基于这一洞察,我们提出了一种非常简单的流程来利用 DiTs 的上下文能力:
- 拼接图像而不是 tokens
- 对多张图像执行联合描述生成
- 使用小规模数据集(例如,20 ∼ 100 个样本)进行特定于任务的 LoRA 微调,而不是使用大规模数据集进行全参数微调
这种方法不需要修改原始的 DiT 模型,只需要更改训练数据。
虽然我们的框架在微调数据方面是特定于任务的,但在架构和流程方面仍然是与任务无关的。
与GDT的区别为:
- 图像拼接:我们是将一组图像拼接成一张大的图像,而不是拼接注意力 tokens。这种方法与 diffusion transformers (DiTs) 中的 token 拼接近似等效,忽略了变分自动编码器 (VAE) 组件引入的差异。
- 提示拼接:我们将每个图像的提示合并成一个长提示,使模型能够同时处理和生成多个图像。这与 GDT 方法不同,在 GDT 方法中,每个图像的 tokens 只会与它自身的文本 tokens 进行交叉注意力交互。
- 使用小数据集进行极小的微调:我们没有在数十万个样本上进行大规模训练,而是使用仅包含 20 到 100 个图像集的小型数据集对模型的低秩适配 (LoRA) 进行微调。这种方法显著减少了所需的计算资源,并很大程度上保留了原始文本到图像模型的知识和上下文学习能力。
Method Link to Method
我们的出发点是假设基础文本到图像模型本身就具备针对不同任务的一些上下文生成能力,即使质量参差不齐。图3中的结果支持了这一点,该模型有效地为不同任务生成了多张图像(有时带有条件)。

基于这一洞察,对大型数据集进行广泛的训练是不必要的;我们可以通过精心策划的高质量图像集来激活模型的上下文能力。
另一个观察是,文本到图像模型可以从包含多个面板描述的单个提示中生成连贯的多面板图像(见图3附录A)。

因此,我们可以通过使用整合的图像提示来简化架构,而不是要求每张图像只关注其各自的文本标记。这使得我们能够重用原始的文本到图像架构,而无需任何结构修改。
我们最终的框架设计通过在训练过程中直接将一组图像连接成一张大型图像来同时生成这组图像,同时将其对应的文本描述合并为一个包含总体描述和每个面板清晰指导的提示。
生成图像集后,我们将大型图像分割成单独的面板。
此外,由于文本到图像模型已经展示了上下文能力,我们不对整个模型进行微调。相反,我们在一小部分高质量数据上应用低秩自适应(LoRA)来触发和增强这些能力。
为了支持对额外的图像集进行条件控制,我们采用了一种免训练方法SDEdit,基于未被遮盖的图像集对一组图像进行修复,所有这些图像都连接在一张大型图像中
从Group Diffusion Transformer到Incontext LoRA
© JuneSnow | CC BY-SA 4.0