
Visual Textualization for Image Prompted Object Detection讲解
Table of Contents
Visual Textualization for Image Prompted Object Detection讲解 Link to Visual Textualization for Image Prompted Object Detection讲解
动机与贡献 Link to 动机与贡献
尽管OVLMs表现突出,但其零样本目标检测(ZSOD)存在三重核心问题:
- 预训练数据偏差:下游任务中的许多目标在预训练数据中覆盖不足,导致迁移性能受限;
- 文本提示语义缺失:自然语言描述难以捕捉细粒度特征,存在语义偏差与信息遗漏;
- 类间文本混淆:相似物体在文本空间中的描述高度重叠(如不同品种的鸟类),仅靠文本难以区分。
这些挑战凸显了引入下游任务视觉信息的必要性。现有少样本目标检测(FSOD)方法虽尝试通过视觉样本微调或结构修改增强模型,但存在破坏OVLM原有目标-文本对齐的风险,进而损害其泛化能力。
图像提示的潜力与现有方案的不足: 以图像作为提示(Image Prompting)为补充文本语义提供了新思路,但多数OVLMs缺乏对图像提示的原生支持。例如,MQ-Det通过在文本编码器中添加可训练交叉注意力模块,使图像提示调制文本Token,但该方法仅重加权现有文本特征,未直接引入新视觉信息,且新增结构可能偏离预训练对齐。此外,OWL-ViT等模型依赖特定预训练架构,难以泛化至其他OVLMs。
本文核心贡献:
- 首次提出视觉文本化概念,实现图像提示对OVLM的无损集成,扩展其检测预训练未覆盖类别的能力;
- 设计MSTB与MSF模块,在保留OVLM原结构的同时,高效利用其预训练知识;
- 在零样本与少样本场景中验证了视觉-文本互补的有效性,为开放词汇目标检测提供了实用方案。
Method Link to Method
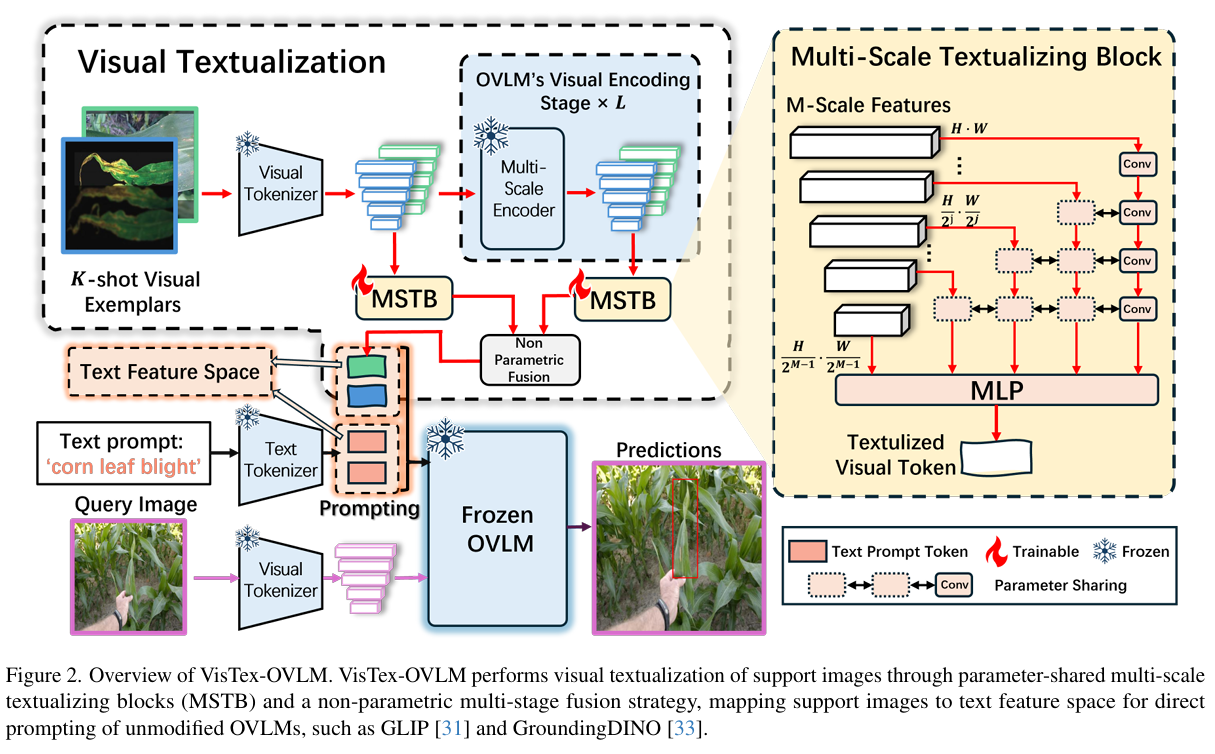
1. 任务定义与 OVLM 基础框架 Link to 1. 任务定义与 OVLM 基础框架
在少样本目标检测(FSOD)中,数据集分为基类集合 和新类集合,其中新类每个类别仅含 K 个标注样本(K-shot)。推理时,支持图像提供视觉示例,查询图像为待检测目标。广义少样本检测(GFSOD)则要求模型同时处理基类与新类,对泛化能力提出更高要求。
目标级视觉-语言模型(OVLMs)的核心设计包括:
- 层次化视觉编码器:生成多尺度区域特征 ,捕捉不同大小的目标;
- 扩展文本编码器:通过短语接地数据扩充词汇表,文本特征 ( P^i ) 与视觉特征对齐;
- 多阶段交叉注意力:通过跨模态交互强化目标-文本语义关联。
其中, 包含 ( M ) 个区域特征, 由文本 Tokenizer 生成,维度为 ,构成 OVLM 的基础编码框架。
2. 视觉文本化:核心原理与实现路径 Link to 2. 视觉文本化:核心原理与实现路径
图像提示工程:从视觉到语义的预处理 Link to 图像提示工程:从视觉到语义的预处理
为最大化少样本标注的有效性,作者采用背景模糊技术处理支持图像:对目标边界框外区域进行高斯模糊,突出前景目标并抑制背景干扰。该策略借鉴语义分割中的图像提示经验,确保支持图像的视觉信息聚焦于目标实例。
3. 多尺度文本化模块(MSTB):视觉特征的文本空间映射 Link to 3. 多尺度文本化模块(MSTB):视觉特征的文本空间映射
MSTB 的核心目标是将支持图像的视觉特征投影到 OVLM 的文本特征空间。具体流程如下:
多尺度特征提取:
跨尺度特征处理:对除最小尺度外的特征使用 卷积(步长 2)下采样,最小尺度直接保留;
参数共享策略:使用共享卷积核处理不同尺度特征;
文本空间映射:通过 MLP 生成文本化视觉特征
融合处理为:
该模块使模型能捕捉细粒度细节与全局上下文,增强新类语义表示。
4. 多阶段融合策略(MSF):跨层级语义整合 Link to 4. 多阶段融合策略(MSF):跨层级语义整合
MSF 的目标是将不同视觉编码器阶段的文本化特征整合为统一视觉 Token。通过非参数化融合:
该策略无额外参数,充分利用 OVLM 多层目标-文本对齐能力。实验显示,全阶段融合(尤其低层)可保留细节与抽象语义的平衡。
多阶段融合的必要性 Link to 多阶段融合的必要性
OVLM 编码器中,低层特征保留更多空间细节,高层更侧重语义抽象。MSF 融合所有层特征,有效提升小目标检测性能,实验显示可提升 12.3% 新类 AP。
5. 推理流程:支持图像提示的无损接入 Link to 5. 推理流程:支持图像提示的无损接入
文本-视觉提示联合编码 Link to 文本-视觉提示联合编码
在推理阶段,VisTex-OVLM 将文本化视觉 Token 与文本提示串联输入:
单样本场景:
K 样本场景:
其中 为目标描述, 为支持图像的文本化特征。该设计保持 OVLM 原有架构与训练权重不变。
训练策略与兼容性 Link to 训练策略与兼容性
MSTB 仅在基类 上训练,使用 OVLM 的原损失函数(如对比损失、边界框回归)。训练阶段,支持图像与文本提示联合编码输入,无需新类微调,适应开放词汇检测。
6. 与现有方法的核心差异 Link to 6. 与现有方法的核心差异
对比 MQ-Det 等图像提示方法,VisTex-OVLM 的独特性在于:
- 无损对齐:不修改结构,通过特征投影引入新类,无需微调;
- 视觉信息直接集成:VisTex-OVLM 独立生成视觉 Token,避免语义丢失;
- 多尺度-多阶段联合优化:MSF+MSTB 充分利用 OVLM 的层次特征,在少样本场景实现强表征学习。
Visual Textualization for Image Prompted Object Detection讲解
© JuneSnow | CC BY-SA 4.0