
Thu Aug 07 2025
1305 words · 14 minutes
Training-free Geometric Image Editing on Diffusion Models讲解
Table of Contents
Training-free Geometric Image Editing on Diffusion Models讲解 Link to Training-free Geometric Image Editing on Diffusion Models讲解
论文介绍 Link to 论文介绍
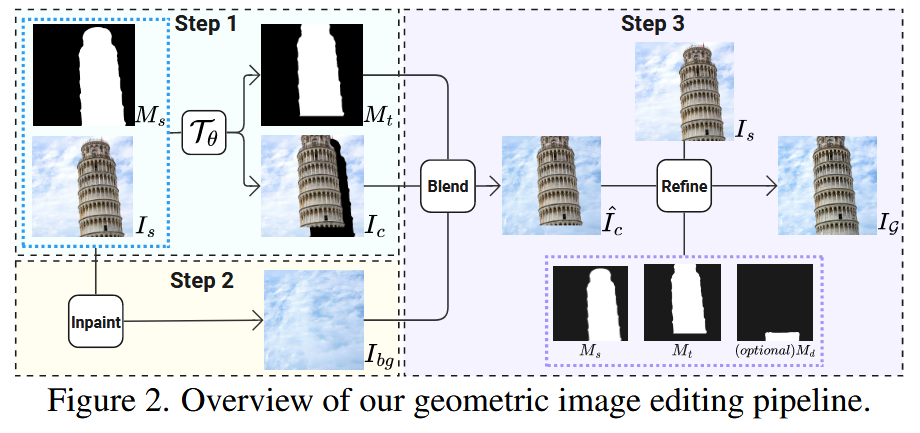
主要是对物体移动位置,然后再融合背景的论文
✅ 1. Temporal Contextual Attention (TCA) Link to ✅ 1. Temporal Contextual Attention (TCA)
📌 目的: Link to 📌 目的:
提升模型在局部区域编辑时的自然性和平衡性,防止过早或过晚地使用全局注意力导致的不一致或缺乏细节。
🧱 背景问题: Link to 🧱 背景问题:
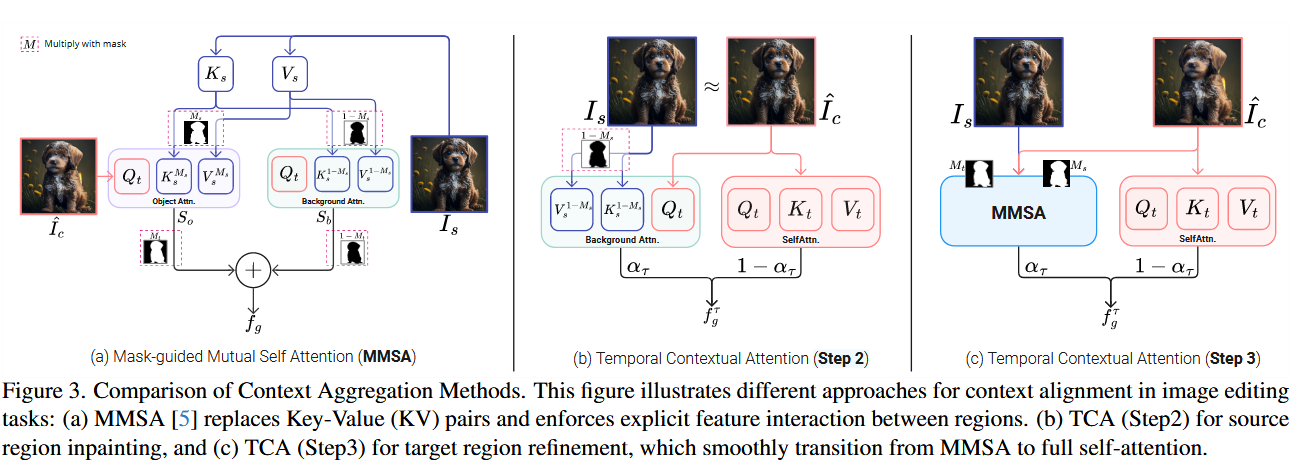
MMSA(Mask-guided Mutual Self-Attention)可以限制注意力区域,但过于刚性。
- 对象区域和背景区域分别用不同的 self-attention 处理:
- 最终组合为:
- 其中:
- :源区域掩码
- :当前时刻的目标掩码
- 限制:
- MMSA 固定只关注被 mask 住的区域,难以生成全局连贯的内容
- 在需要细节增强时效果不佳,尤其当修改区域与原图融合边界模糊时
传统做法使用固定阈值切换 MMSA 和 Self-Attn,效果不稳定。
TCA 提出一种时间依赖的注意力融合机制,自动平滑过渡。
⚙️ 方法核心: Link to ⚙️ 方法核心:
在不同扩散步 动态混合 MMSA 和 Self-Attn:
其中:
- :当前 latent 的全图 self-attn 输出
- :MMSA 输出(对象区域与背景)
- :线性从 1 变 0,随时间推进
🧪 应用策略: Link to 🧪 应用策略:
- Step 2(背景重建):使用掩码 ,只重建背景。
- Step 3(结构补全):使用 ,专注结构补全。
✅ 总结: Link to ✅ 总结:
TCA 实现 注意力策略的平滑过渡,兼顾局部控制与全局一致性,是结构编辑中协调性和自然性的关键模块。
✅ 2. Local Perturbation (LP) Link to ✅ 2. Local Perturbation (LP)
📌 目的: Link to 📌 目的:
允许模型在指定区域中引入更多随机性,从而完成大幅度结构改动(如修复遮挡、生成缺失),同时保持其他区域不变。
🧱 方法: Link to 🧱 方法:
在局部区域 使用 DDPM(引入随机性),其余区域使用 DDIM(确定性):
🧪 应用策略: Link to 🧪 应用策略:
- Step 2:(原始 mask)
- Step 3:(结构补全区域)
✅ 总结: Link to ✅ 总结:
LP 增强了编辑区域的灵活性与重构能力,适用于遮挡恢复、形状变更等需要强结构改动的场景。
✅ 3. Content-specified Generation (CG) Link to ✅ 3. Content-specified Generation (CG)
📌 目的: Link to 📌 目的:
控制生成语义,解决 LP 中生成内容不可控的问题。通过用户文本 指定“在什么区域生成什么内容”。
🧱 方法: Link to 🧱 方法:
1. Cross-Attention(掩码 控制语义注入区域): Link to 1. Cross-Attention(掩码 \mathcal{M}_1 控制语义注入区域):
- 在 区域引入带语义的 cross-attention,其余用空文本 embedding 保持原样。
2. Classifier-Free Guidance(掩码 控制引导区域): Link to 2. Classifier-Free Guidance(掩码 \mathcal{M}_2 控制引导区域):
- 仅在 区域应用 CFG,增强语义一致性,防止对不相关区域造成影响。
🧪 应用策略: Link to 🧪 应用策略:
- Step 2:
- Step 3:,
✅ 总结: Link to ✅ 总结:
CG 提供语义级别的精确控制,使用户能够通过文字描述在特定区域生成特定内容,兼顾自由度和准确性。
Thanks for reading!
Training-free Geometric Image Editing on Diffusion Models讲解
© JuneSnow | CC BY-SA 4.0