
Table of Contents
Reflect-DiT讲解 Link to Reflect-DiT讲解
Motivation Link to Motivation
在文本到图像生成领域,提升性能的主要方法一直是训练时扩展,即在更多数据上使用更大的计算资源训练更大的模型。
虽然这种方法有效,但其计算成本高昂,因此人们越来越关注推理时扩展以提高性能。
目前,文本到图像扩散模型的推理时扩展主要限于best of N采样,即为每个提示生成多张图像,然后由选择模型选出最佳输出。
受到DeepSeek-R1等推理模型在语言领域近期成功的启发,我们为文本到图像扩散Transformer引入了一种替代朴素Best of N采样的方法,赋予其上下文反思能力。
我们提出了Reflect-DiT,该方法使扩散Transformer能够利用先前生成的图像及其文本反馈(描述必要的改进)作为上下文示例来改进其生成结果。Reflect-DiT并非被动地依赖随机采样并寄希望于未来的生成能有所改善,而是明确地调整其生成过程以解决需要改进的具体方面。
Method Link to Method
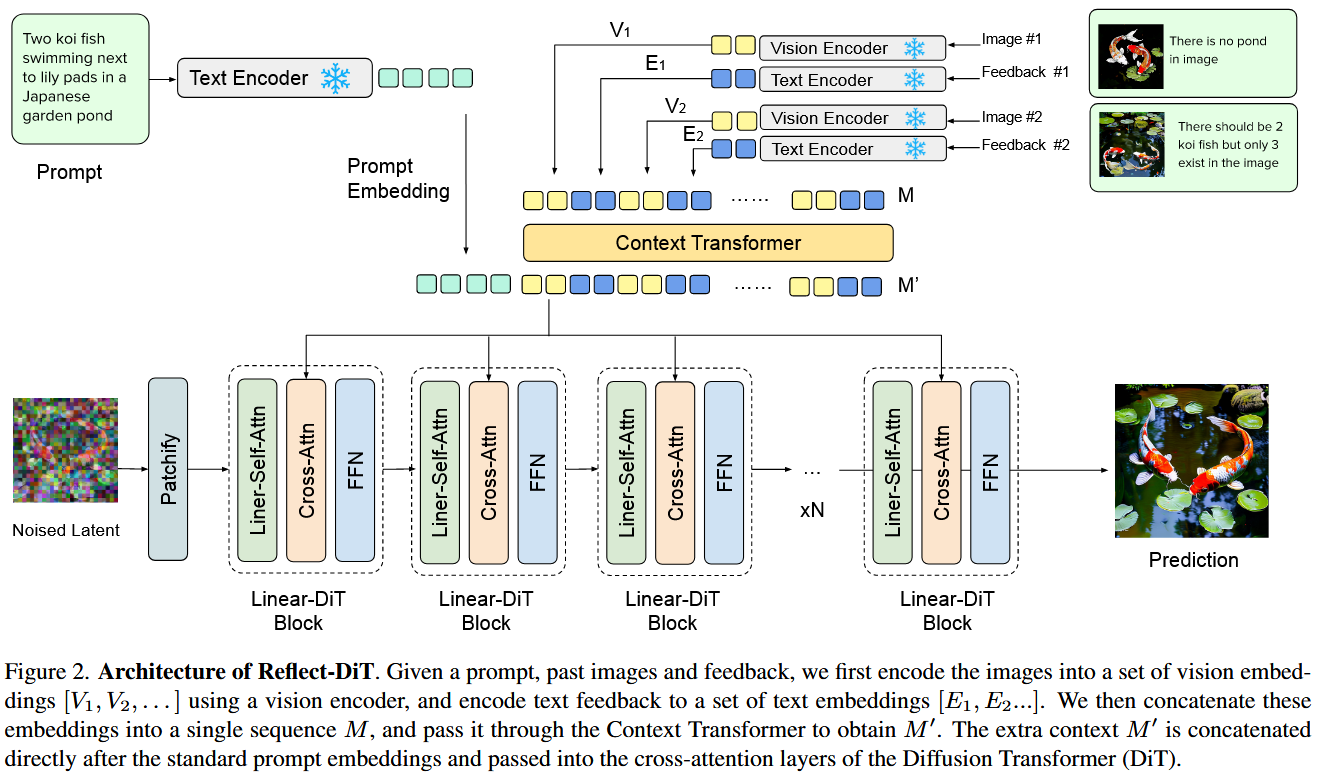
- 每次得到的图片经过VLM得到结果,经过encoder编码再和之前的prompt一起进入DiT,作为condition一起生成新图,不断修正
Thanks for reading!