
Table of Contents
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers Link to OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
https://arxiv.org/abs/2505.21448
1 引言
传统的唇形同步方法严重依赖于参考帧结合掩码帧修复(masked-frame inpainting)。
问题:当目标姿态与参考姿态差异显著时,这些方法在处理头部姿态变化、身份保留和伪影消除方面效果差。
对显式掩码的依赖无法完全防止不必要的唇形泄漏(lip shape leakage),从而损害同步质量并限制了其在各种视觉表现形式中的适用性。 本该被音频驱动的新唇形没有完全替换掉原视频的唇形,导致原视频的嘴型“漏”到了生成结果里。
与强视觉线索不同,音频信号提供的条件相对较弱,使得精确的唇形同步变得困难。
此外,现有方法依赖于人脸检测和对齐技术,这些技术在==应用于风格化角色和非人类实体时会失效==,而这些恰恰是现代文本生成视频模型擅长生成的丰富内容。
Audio-driven Portrait Animation:image-to-video框架,对头部姿态或面部表情没有约束,不是生成内容整合回原始视频
Lip synchronization:video-to-video框架,仅修改嘴唇运动,同时保持与现有镜头的兼容性
3 方法 Link to
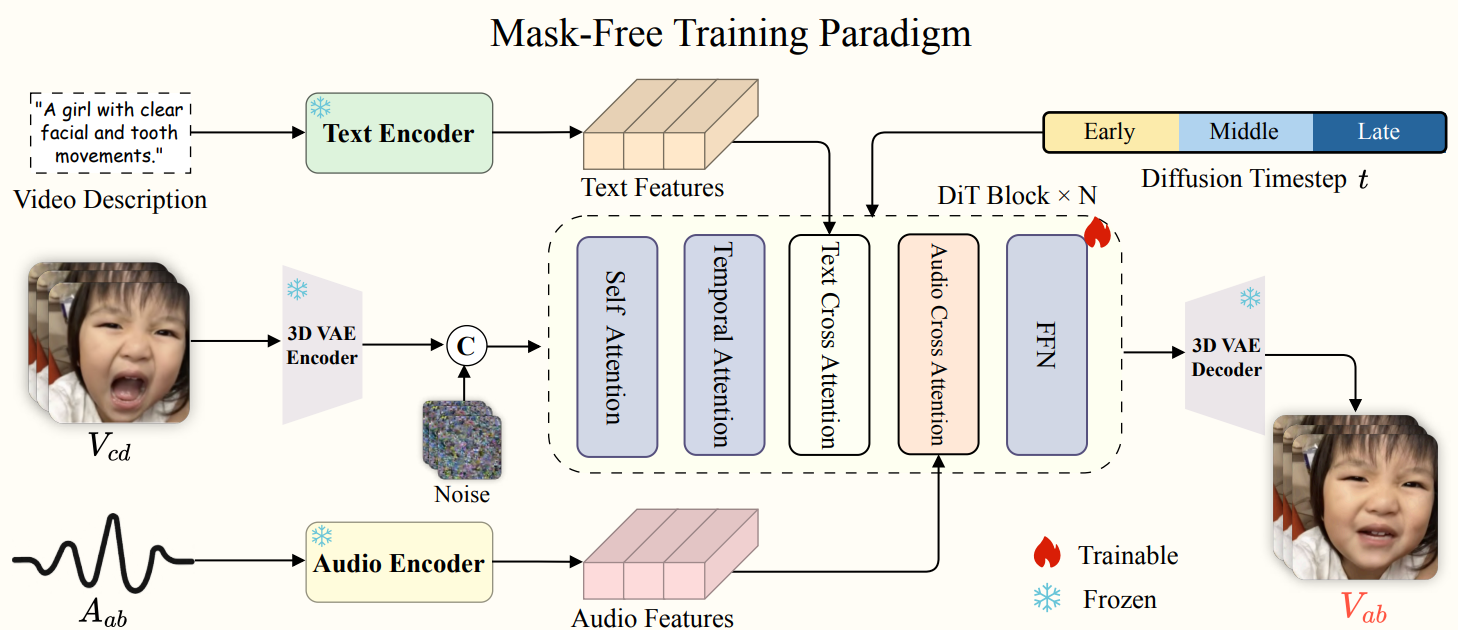
3.2 无掩码训练范式 Link to
- masked-frame inpainting:需要显式的人脸检测和对齐,在处理风格化角色和非人类实体时会失效。
- 直接帧编辑:需要具有相同头部姿态和身份的完美配对训练数据——仅在嘴唇运动上有所不同。配对数据少,且会模型对多样化视觉结果的泛化能力差。
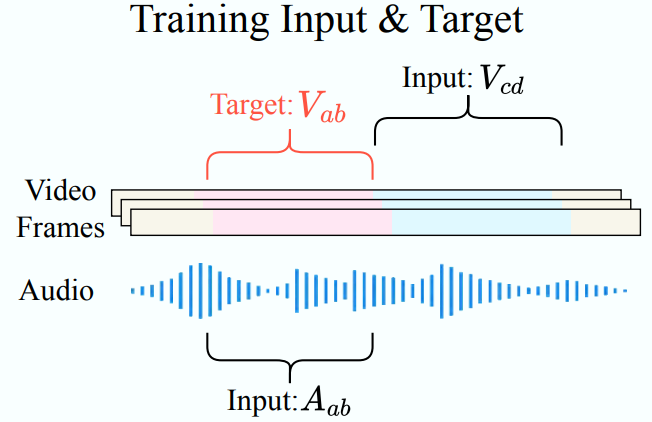
目标:通过迭代去噪学习一个条件生成过程映射 ,其中 代表视频帧, 代表音频。
其中 代表在时间步 时目标视频 的加噪版本
用于训练的 损失定义为:
时间步依赖采样策略(Timestep-Dependent Sampling Strategy)
扩散模型:
- 早期时间步侧重于生成基本的面部结构,包括姿态和身份信息;
- 中期时间步主要生成由音频驱动的嘴唇运动;
- 而晚期时间步则完善身份细节和纹理。
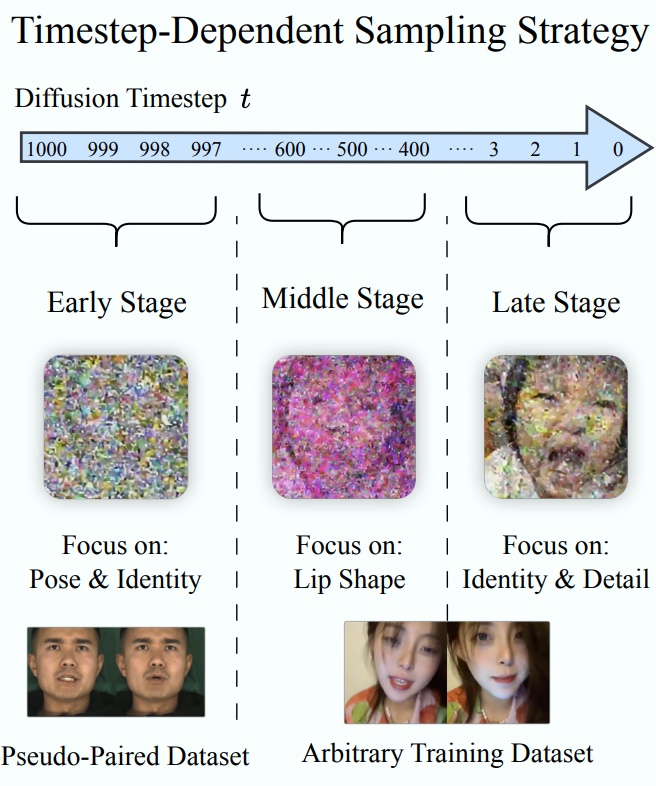
在不同的时间步使用不同的数据集。
早期时间步(大约 ),采用来自受控实验室设置的伪配对(pseudo-paired)数据:这些样本保持几乎相同的姿态信息,仅在嘴唇运动上有所变化。
MEAD 数据集 作为伪配对数据的来源。MEAD 数据集在实验室条件下拍摄,具有以下优势:
– 固定拍摄条件:
同一主体的多种情绪表达在固定机位和一致光照下录制。 这确保面部结构与身份保持稳定,仅在唇形和表情上变化。
– 自然伪配对:
同一身份下,不同语句的帧拥有几乎相同的头部姿态和环境条件,仅唇形不同。
– 多视角拍摄:
MEAD 的多视角设置进一步提升数据一致性,使模型能更稳健地学习姿态不变的面部结构。
中期和晚期时间步:过渡到更多样化的数据,从任意视频中进行采样。
这里, 表示从具有最小姿态变化的受控数据集中采样, 表示从多样化的视频集合中采样
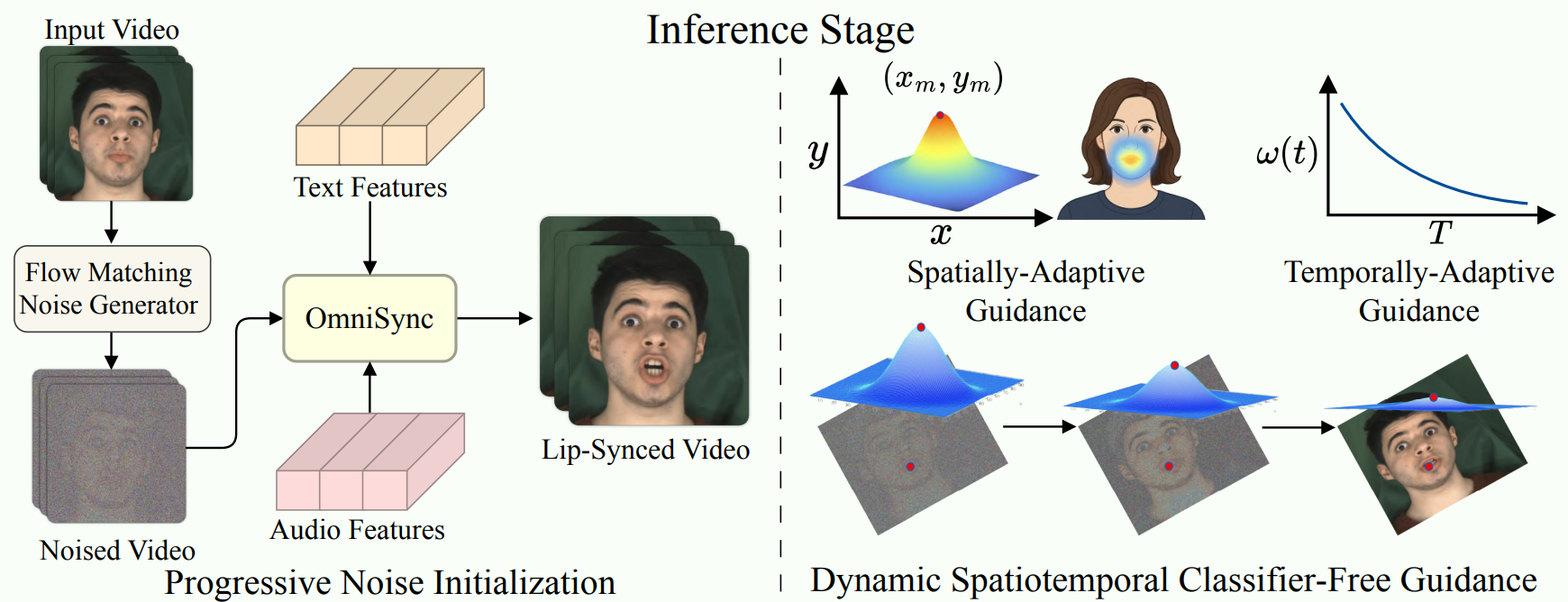
3.3 渐进式噪声初始化 Link to
标准的基于扩散的生成通常从随机噪声(时间步 )开始,并向最终输出(时间步 0)逐渐去噪:导致生成内容与原始视频帧之间出现细微但明显的姿态错位,产生不希望的边界伪影并损害身份保留。
根本问题在于:扩散早期阶段的误差累积影响大。
流匹配噪声初始化(Flow-Matching Noise Initialization)
不是在时间步 从随机噪声开始扩散过程,而是从带有受控噪声水平的原始视频帧进行初始化。这模拟了扩散轨迹中的中间状态,对应于归一化参数 。
初始化:向原始视频帧添加受控噪声
是源视频帧
设 为对应于此初始化点的离散时间步( 是扩散步数的总数,且 )。
优势
- 首先,它绕过了扩散的早期阶段(从 到 ),即形成一般面部结构的阶段。这确保了头部姿态和全局结构直接继承自源帧。
- 其次,它通过仅对剩余步骤(从 到 0)执行去噪来减少计算需求。
3.4 动态时空无分类器引导 Link to
空间自适应引导(Spatially-Adaptive Guidance)
空间适应的关键见解是,==音频信息主要影响嘴部区域==,而其他面部区域应基本保持不变。
通过一个高斯加权空间引导矩阵来实现这一点,该矩阵==将引导强度集中在语音相关区域周围==:
其中 代表嘴部中心, 控制高斯分布的扩散范围, 是应用于非嘴部区域的基线引导强度, 是应用于嘴部中心的峰值强度。这种空间适应确保了音频条件强烈影响嘴唇及周围区域,同时最小化对其他面部特征的影响。
时间自适应引导(Temporally-Adaptive Guidance)
我们观察到,音频条件在扩散过程的不同阶段扮演着不同的角色。
在早期扩散时间步,强引导有助于建立正确的唇形,而在后期阶段,过度的引导会破坏精细的纹理细节。
一个随时间递减的引导计划:
其中 是当前的扩散时间步, 是时间步总数, 是最大引导比例, 控制衰减率,取值为 1.5。这种时间适应确保在形成粗糙结构的早期和中期扩散阶段进行强引导,并在精细细节和纹理完善的后期阶段逐渐减少影响。
统一动态时空 CFG(Unified Dynamic Spatiotemporal CFG)。
结合空间和时间适应,我们的 方法将标准 公式修改为:
其中 和 分别是带有和不带有条件的噪声预测。通过这种 ,我们的方法实现了对生成过程的精确控制,有效地解决了音频驱动生成中的弱音频信号问题。