https://arxiv.org/abs/2508.14033
https://github.com/MeiGen-AI/InfiniteTalk
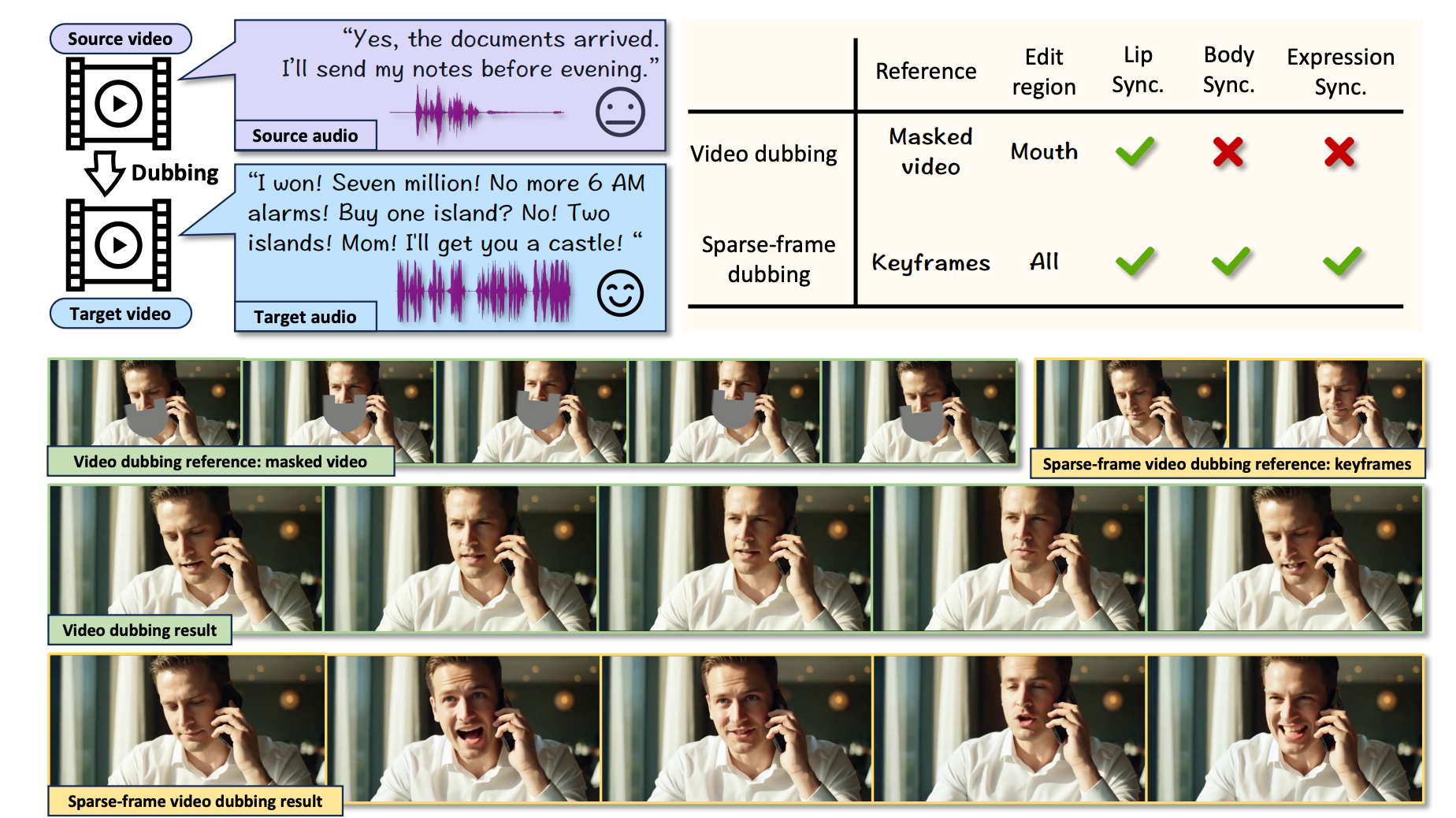
传统的视频配音技术仍然受限于嘴部区域的编辑,导致面部表情和身体姿态不协调,从而降低了观众的沉浸感。
sparse−frame video dubbing通过策略性地保留参考关键帧来维持人物身份、标志性姿态和相机轨迹,同时实现整体的、与音频同步的全身动作编辑。
仅参考选定的关键帧以保留原始视频的情感节奏、标志性手势和相机轨迹,同时释放面部表情、头部运动和身体动态,以便与配音音频有机同步。
作为一项长视频生成任务,需要强大的时间连续能力。一个切实可行的解决方案是使用具有初始和末尾帧指导的音频条件视频生成器。
一些模型简单地应用音频条件image-to-video生成器问题:
- 长时间生成过程中根本难以保持身份(identity preservation)
- 默认对条件帧进行严格的动作复制。
- 简单地应用初始和末尾帧条件会产生突兀的块间过渡(inter−chunk transitions)。
用于音频驱动视频生成的条件流匹配
流匹配视频生成模型采用神经网络,通过建模一个随时间步变化的向量场来生成逼真的视频帧,该向量场将样本从噪声分布传输到目标视频分布。
给定一个真实条件视频分布 q(x∣c),其中 x∈Rt×h×w×c 是编码的视频潜在变量。
c={y,a,xref},y∈Rm×dtext,a∈Rn×daudio,xref∈Rtref×h×w×c 是条件,包括文本提示嵌入、音频嵌入和参考帧潜在变量。
条件流匹配通过使用连续变量 t∈[0,1] 在 q(x∣y,a) 与已知平凡分布(例如高斯噪声)p(x∣y,a) 之间进行插值,从而定义了一系列分布。
qt(x∣y,a)=(1−t)⋅p(x∣y,a)+t⋅q(x∣y,a).(1)具体而言,可以通过 xt=(1−t)⋅x1+t⋅x0 在 x0∼p(x∣y,a) 和 x1∼q(x∣y,a) 之间进行插值来获得随机变量 xt∼qt(x∣y,a)。
由 θ 参数化的生成模型 vθ(⋅) 被训练以匹配连续速度场 vθ(xt∣y,a)≈dtdxt。为了实现这一点,我们采用条件流匹配目标:
Lfm=Et,x0,x1∥vθ(xt∣y)−(x1−x0)∥22.(2)可以使用 ODE 求解器从流匹配生成模型中进行采样。
稀疏帧视频配音
视频配音通过用翻译后的语音替换原始音频来本地化内容,同时保持视觉真实性。
正如本工作所形式化的那样,该任务将源视频潜在变量 x0∈Rt×h×w×c 和目标音频 a∈Rn×daudio 转换为输出视频,其中嘴唇运动、面部表情和身体动态与新音频有机同步。
传统的视频配音技术完全专注于口腔区域修复——编辑嘴唇运动,同时冻结头部旋转、面部表情和身体姿态 Li et al. (2024)。这造成了破坏沉浸感的错配,因为静态的肢体语言与充满情感的演讲相矛盾(例如,在激情的对话中保持僵硬的姿势)。
如图 1 所示,稀疏帧视频配音从根本上重新定义了这一过程:它仅保留选定的关键帧 xref 以锚定身份、情感节奏、标志性手势和相机轨迹——这对于视觉连续性至关重要——同时释放全身动态(面部表情、头部运动、身体手势)以与配音音频有机同步。
如图 1 所示,这种范式转变实现了逼真的对齐,头部转动跟随语音节奏,手势增强情感基调——这是仅靠嘴唇编辑无法实现的。至关重要的是,稀疏帧配音在无限长序列上运行,要求生成延续性超出短片,以在长时间内保持同步,这是传统逐帧修复无法实现的能力。
3.2 对朴素解决方案的观察 Link to
本节使用两个基线模型:图像转视频(I2V)Cui et al. (2024) 和首尾帧转视频(FL2V)Wan et al. (2025),研究了稀疏帧视频配音的实用方法。
如图 2 所示,这两种方法在生成长视频序列时都表现出严重的局限性。
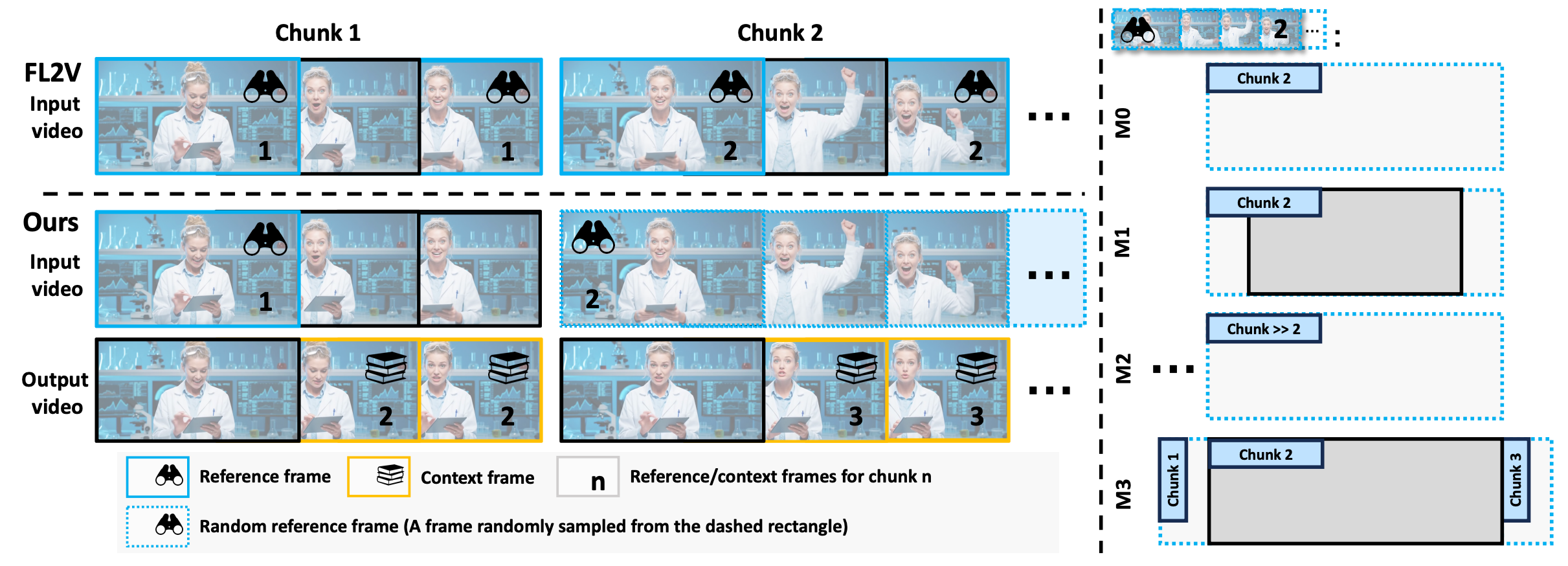
I2V 方法的操作方式是==从单个参考帧(例如源视频的起始关键帧)初始化视频的第一个块。对于随后的块,它仅使用前一个块生成的最后一帧作为新的参考==。虽然这==保留了运动灵活性,但由于缺乏对原始关键帧的持久锚定,导致了误差累积==:身份(例如,面部特征逐渐偏离源演员)和色调(例如,背景色调在不同块之间发生偏移)的细微差异随时间推移而复合,导致明显的退化。
FL2V 方法将==输入片段的起始帧和结束帧作为每个块的条件,从而确保与源视频参考姿态的对齐==。这==消除了累积误差,但引入了一个新问题:模型通过在相应的时间戳严格复制参考帧来实施刚性控制==。这与稀疏帧配音所需的软条件(soft conditioning)相矛盾,即全身动作必须动态适应音频线索。
至关重要的是,两种方法都存在==突兀的块间过渡(inter−chunk transitions)。由于它们仅依赖于静态图像条件(例如 I2V 的单帧或 FL2V 的两个固定帧),它们缺乏应在块之间传递的动量信息==。
这些观察结果凸显了一个基本的权衡:I2V 优先考虑运动流畅性,但以累积误差为代价;而 FL2V 优先考虑参考保真度,但以牺牲运动自然度为代价。
3.3 带有参考帧的音频驱动流式视频生成器 Link to
该框架采用上下文帧(context frames),即每个先前生成的块的尾部片段,将运动动量(kinetic momentum)传播到后续片段中。
通过通过DiT处理这些帧,模型维持了运动的连续性。
为了消除累积误差,我们采用类似于 FL2V 多帧条件的策略,从源视频中动态采样多个参考帧。这些关键帧保留了关键的视觉属性,包括身份、背景细节、相机轨迹和风格元素。
至关重要的是,不同于 FL2V 对固定位置参考帧的刚性复制(这会抑制自然运动),我们的模型有潜力实现 3.4 节所讨论的软条件(soft conditioning)。
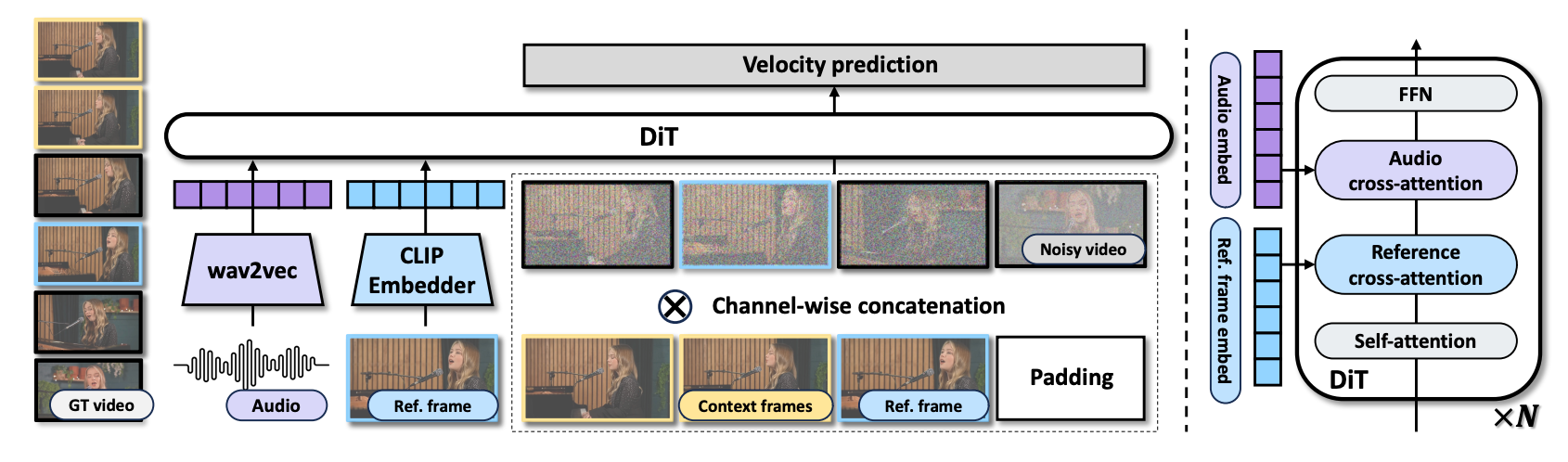
模型草图如图 4 所示。该模型由音频嵌入器、视频 VAE 和扩散 Transformer (DiT) 组成。
模型的训练方式
为了训练该模型,我们不需要配音视频对(dubbed video pair),只需要一个带有音频轨道的视频。
给定一个源视频,参考帧是从视频中均匀随机采样的。
在训练期间,上下文帧是源视频的前 4(tc−1)+1 帧。
VAE 编码之后,得到参考帧潜在变量 xref∈Rc×1×h×w、完整源视频潜在变量 xfull∈Rc×(t+tc)×h×w、上下文帧潜在变量 xcontext∈Rc×tc×h×w 以及后续帧潜在变量 x0∈Rc×t×h×s,其中完整视频潜在变量是上下文帧潜在变量 xcontext 和后续帧潜在变量 x0 的组合,即 xfull={xcontext,x0}。
源视频中的音频序列被编码以获得嵌入 a。
不失一般性,我们在本节展示条件流匹配中 t 时刻的训练过程。
单位高斯噪声被用作平凡分布。噪声潜在变量由 xt=(1−t)⋅x1+t⋅x0,x1∼N(0,I) 导出,其中 x1 是与 x0 具有相同维度的高斯噪声。
DiT 模型使用条件 c={y,a,xref,xtran} 构建场估计器 vθ(xt∣c)。
具体而言,我们首先在时间维度上拼接噪声潜在变量 xt 和干净的上下文帧 xcontext 以获得 z1∈Rc×(t+tc)×h×w。
然后我们将参考帧填充到时间长度 tc+t 以获得 z2∈Rc×(t+tc)×h×w。
最后,我们在通道维度上拼接 z1,z2 和参考帧指示掩码 m∈R4×(t+tc)×h×w。数学上,该过程为:
z1z2mz=concat((xcontext,xt),2)=concat((xref,0),2)=concat((1,0),2)=concat((z1,z2,m),1)其中 concat(⋅) 是拼接操作符(例如,concat((xcontext,xt),2) 将 xcontext 和 xt 在第 2 维度上拼接)。
0 和 1 是维度为 0∈R4×(t+tc−1)×h×w,1∈R4×1×h×w 的零张量和一张量。
如图 4(右侧)所示。
在我们的 Transformer 模型中,有一个音频交叉注意力模块(audio cross−attention)和一个图像交叉注意力模块(image cross−attention),实现了音频和参考图像的调节。
参考帧在输入 DiT 之前由 CLIP 处理以获得嵌入 zref。为了训练该模型,我们采用条件流匹配目标
Lfm=Et,x0,x1,c∥vθ(xt∣c)−(x1−x0)∥22.采样方法
自回归地生成小视频块(small video chunks)来生成整个长视频序列。
在第一个视频块中,使用输入视频的第一帧作为参考帧,并且不需要上下文帧。
在随后的视频块中,我们使用前一个输出视频块的最后 4(tc−1)+1 帧作为上下文帧,并使用输入块的第一张图像作为参考帧。
相机控制
我们在本节探讨在稀疏帧视频配音中解决相机运动保留的方法。参考帧的使用提供了对相机轨迹的全局控制。
然而,每个视频块内的详细相机运动是不受控制的,并且可能与源视频相矛盾。为了解决这个问题,我们使用了两个插件,包括 SDEdit 和 Uni3C。SDEdit 通过以比例 t0 将源视频添加到初始化噪声中来整合轨迹信息。去噪采样过程从 t=t0 而不是 t=1 开始。xt0=(1−t0)⋅x1+t0⋅x0。Uni3C 通过部署类似 ControlNet 的架构来注入相机运动。我们的实验中展示了这些方法之间的比较。
来自参考帧的控制强度
本节探讨了在稀疏帧视频配音中实现软调节(soft conditioning)的策略,其中模型必须生成音频对齐的全身动作,而无需严格复制可能与配音语音冲突的参考帧。
同时,我们期望模型具有自适应控制强度:
- 当参考帧与上下文帧相似时,控制强度较弱,以便模型产生多样化的动态。
- 当参考帧与上下文帧截然不同时,控制强度较强,以确保身份和背景的一致性更好。下面,我们展示对符合这些要求的训练策略的分析。
我们从模型 M0 开始我们的调查,该模型在训练期间从当前源输入视频块中均匀随机采样参考帧。
如图 3 所示,这种方法表现出过度的控制强度。模型在任意时间戳不适当地复制参考内容,例如在情绪中性的演讲期间复制拍打前额的动作,破坏了视听同步。
为了系统地分析参考帧定位如何控制控制保真度,我们检查了两个粒度维度:块级定位(选择哪个时间段提供参考)和帧级定位(选择该段内的特定帧)。
我们训练了三个模型变体来隔离这些影响。
- 模型 M1 ==仅从输入块的第一帧或最后一帧采样参考==。这种策略反映了 FL2V 的刚性,强制生成的视频在块边界处精确复制参考姿势,即使它们与音频的情感节奏相矛盾。
- 模型 M2 从==时间上遥远的块(例如,相隔 >5 秒的片段)采样参考==。虽然这充分削弱了控制以避免复制,但它在长序列中引入了累积的颜色和背景误差,表明保真度保留不足。
- 模型 M3 从==相邻块(例如,输入 1 秒内)采样参考==。这种配置实现了适度的控制强度:参考帧保留了身份和相机运动而没有精确复制,同时完全消除了累积误差。
我们的实验结论性地证明,块级距离是调节控制强度的主要因素。
较短的时间距离(如在 M3 中)创造了一种最佳平衡:它们将视觉一致性锚定在源视频上,同时释放面部表情、头部旋转和身体手势以与音频有机同步。
较长的距离(如在 M2 中)会降低保留能力,导致输出不稳定。
固定边界采样(如在 M1 中)优先考虑复制而非表现力,扼杀了运动动态。
因此,M3 的近块定位(near−chunk positioning)成为软调节的基础策略——实现了忠实而灵活的视频配音,使动作与语音和谐共存。