Sun Sep 21 2025
3186 words · 25 minutes
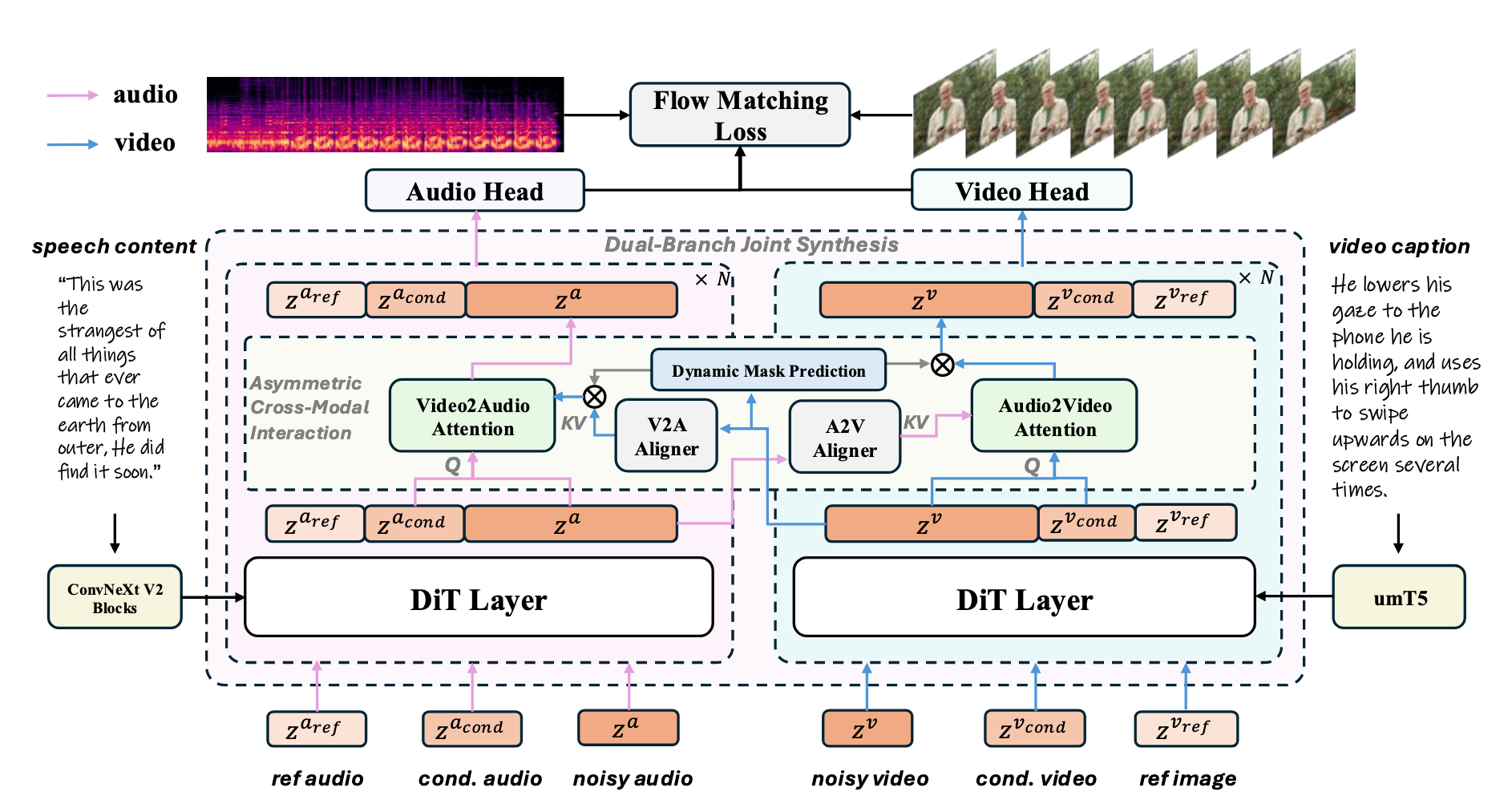
UniAVGen
UniAVGen 接受一个参考说话者图像 Iref、一个视频提示 Tv(描述所需的运动或表情的字幕),以及语音内容 Ta(要说出的文本)作为输入。此外,它支持通过可选的参考音频片段 Xaref 来指定目标声音,并通过以现有条件音频 Xacond 和视频 Xvcond 为条件来实现音视频的接续。
引入了一个基于对称设计的双分支联合合成框架。
视频分支主干: **Wan 2.2-5B 视频生成模型 **
音频分支主干:Wan 2.1-1.3B 的架构模板——与 Wan 2.2-5B 具有相同的整体结构,仅在通道数上有所不同。
这种对称策略确保了两个分支都以等效的表征能力开始,并在所有级别的特征图之间建立了自然的对应关系。
这种结构上的均等性是实现有效跨模态交互的基石,从而提升了音视频同步和整体生成质量。
视频分支
视频首先以每秒 16 帧的速度进行处理,并使用Wan2.2-5B的VAE编码成潜在表征 zv。
参考说话者图像 Iref 和条件视频 Xvcond 也分别编码成潜在嵌入 zvref 和 zvcond
视频分支的输入 ztv 通过拼接这三个潜在分量得到: ztv=[z0v,zvref,zvt]⊤。
对于视频字幕 Tw,它通过 umT5 编码成 ev,其嵌入通过交叉注意力馈入DiT。
遵循流匹配范式:在这里,模型 uθv 训练用于预测向量场 vt,训练目标公式为
Lv=∣∣vt(ztv)−uθv(ztv,t,ev)∣∣2音频分支
遵循文本转语音 (TTS) 中的常见做法,音频首先以 24,000 Hz 采样并转换为 Mel 语谱图,作为音频的潜在表征 za。
参考音频 Xaref 和条件音频 Xacond 也被转换成它们各自的潜在表示 zaref 和 zacond。
然后,这三个潜在分量沿着时间维度进行拼接,构成音频分支的输入 zta=[z0a,zacond,zta]⊤。
音频分支的训练目标公式为:
La=∣∣vt(zta)−uθa(zta,t,ea)∣∣2其中 ea 表示通过 ConvNeXt Blocks 提取的语音内容 Ta 的特征,通过交叉注意力进一步注入到 DiT 层中,确保音频生成过程与目标音频的声学信息紧密耦合。
虽然双分支结构建立了结构均等性,但要实现鲁棒的音视频同步需要深度跨模态交互。
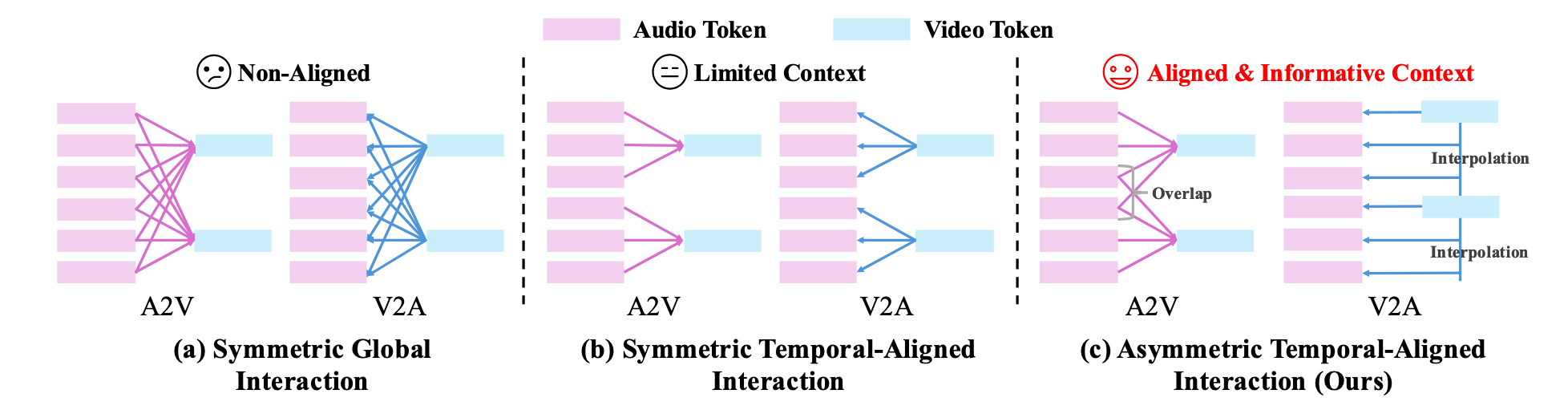
先前的工作主要采用了两种设计实现这一点:
第一种是全局交互,如图 3(a) 所示,其中每个模态的 token 都与另一个模态的所有 token 进行交互。虽然简单,但这需要高训练成本才能收敛到高性能,因为它缺乏明确的时间对齐。
也就是A2V的每一秒视频都和全部语音交互,V2A同理
第二种是时间对齐交互 [38],如图 3(b) 所示,其中每个视频 token 与其对应时间间隔内的音频 token 进行相互作用。这种方法通常收敛更快,但限制了交互期间的上下文信息访问。
也就是A2V的视频的某一秒只和音频的同一时间段交互
为了更好地平衡收敛速度和性能,引入了一种新颖的非对称跨模态交互机制,该机制由两个专门的对齐器组成,分别针对每个模态的独特特征。
音频到视频 (A2V) 对齐器 :
A2V 对齐器通过将细粒度的音频线索注入视频分支,确保精确的语义同步。
我们首先重塑隐藏特征以匹配它们的时间结构:
- 视频 token Hv∈RLv×D 被重塑为 H^tv∈RT×Nv×D(其中 T 表示视频潜在帧的数量,Nv 是每帧的空间 token 数量)
- 音频 token Ha∈RLa×D 被重塑为 H^a∈RT×Na×D
与图 3(b) 不同,我们为每个视频帧创建一个语境化音频表征,认识到视觉发音受到先前和后续音素的影响。
对于第 i 个视频潜在帧,我们通过拼接其邻近帧的音频 token,构建一个音频上下文窗口 Cia=[H^i−wa,…,H^ia,…,H^i+wa],窗口大小为 w。
边界帧通过复制第一帧或最后一帧的特征进行填充。
==也就是多看一点点前后文,并且有个overlap的操作==
随后执行逐帧交叉注意力,其中每个帧的视频潜在查询对应的上下文音频潜在:
H^iv=Wov[H^iv+CrossAttention(Q=WqaH^iv,K=WKaCia,V=WVaCia)].视频到音频 (V2A) 对齐器。
相反,V2A 对齐器将说话者视觉身份(例如,音色、情感)派生的属性嵌入到生成的音频中。
在这里,时间不匹配更为突出,因为每个视频潜在帧映射到一个 k 个音频 token 块。
举例:1s生成16帧视频。音频是以更小、更密集的 token 为单位的,则一帧视频的时间长度内**( 161 秒),可能有 k 个音频 token 需要生成。
时间不匹配:视频的一帧跨越了 k 个音频 token 的时间。
为了实现捕捉平滑视觉过渡的细粒度对齐,采用了一种临时邻域插值策略。
对于每个音频 token j(对应于视频潜在帧 i=⌊j/k⌋),计算两个时间上相邻帧的潜在(帧 i 和后续帧 i+1)的线性插值加权平均,得到一个插值视频上下文Cjv=(1−α)H^iv+αH^i+1v,其中 α=(jmodk)/k.
| 音频 Token j | 相对位置 jmodk | 插值系数 α | **视觉上下文 **Cjv | 解释 |
|---|
| j=0 | 0 | α=0/4=0 | 1.0×H^iv+0×H^i+1v | 完全看当前帧 i,因为这是时间起点。 |
| j=1 | 1 | α=1/4=0.25 | 0.75×H^iv+0.25×H^i+1v | 更多地看 i 帧,少量地看下一帧 i+1。 |
| j=2 | 2 | α=2/4=0.5 | 0.5×H^iv+0.5×H^i+1v | 平均地看 i 帧和 i+1 帧。 |
| j=3 | 3 | α=3/4=0.75 | 0.25×H^iv+0.75×H^i+1v | 更多地看下一帧 i+1,为接下来的音频生成做准备。 |
对于最后一个音频 token 块,简单地使用 Cjv=H^T−1v。这种插值上下文提供了一个平滑、时间感知的视觉信号。
最后,我们执行交叉注意力,其中每个音频潜在查询其对应的插值视频上下文:
H^ja=Woa[H^ja+CrossAttention(Q=WqaH^ja,K=WKvCjv,V=WVvCjv)]最后,H^a 和 H^v 被重塑以匹配 Ha 和 Hv 的维度,并作为附加特征重新注入:
Hv=Hv+H^v Ha=Ha+H^a为了不损害每个模态在训练开始时的生成能力,输出矩阵 Wov 和 Woa 都被初始化为零。
对于音视频联合生成,关键的语义耦合绝大多数集中在面部区域。
强迫交互处理整个场景是低效的,并可能在训练早期引入虚假相关性,从而破坏背景元素的稳定。
为了解决这个问题,提出了一种面部感知调制 (Face-Aware Modulation) 模块,该模块动态地将跨模态交互引向面部区域。
动态掩码预测
引入了一个轻量级的辅助掩码预测头,它作用于去噪网络内的视频特征 Hvl。
该头部应用层归一化 L、一个学习的仿射变换、一个线性投影和一个Sigmoid 激活
生成一个软掩码 Ml∈(0,1)T×Nv:Ml=σ(Wm(γ⊙LayerNorm(Hvl)+β)+bm),其中 ⊙ 是逐元素乘法。
为了确保预测的掩码为人类指导,我们不仅监督其与原始的去噪目标,还施加了一个额外的掩码损失 λmLm: λmLm=λm∣∣Ml−Mgt∣∣22,其中 Mgt 是使用真实人脸掩码计算得到的。
==预测掩码和真实人脸掩码比较==
同时,为了避免在较早的训练阶段过度约束跨模态交互,超参数 λm 随着时间逐渐衰减到 0。
掩码引导的跨模态交互
预测的面部掩码 Ml 通过两种不同的机制细化我们非对称对齐器中的跨模态交互:
A2V 交互的选择性更新:
Hvl=Hvl+Ml⊙Hˉvl其中Hˉvl表示 A2V 交叉注意力的输出。
效果:
这确保了音频信息在训练早期优先调制面部显著区域,同时抑制背景。
V2A 交互:
为了使显著区域的信息能够转移到音频分支,调制视频特征 Hvl 为 Hvl⊙Ml,然后将其用作计算 Cjv的输入。
CFG的传统设计本质上是单模态的。
在多模态的联合合成应用中,其中每个分支都独立地由其文本提示引导音频驱动视频同步或视频影响音频的指导没有被明确体现,限制了模型在音视频同步方面的能力。
为了解决这个问题,提出了模态感知无分类器指导 (MA-CFG),这是一种新颖的方案,用于加强跨模态条件作用机制。
关键见解在于,一个单一、共享的无条件估计可以同时指导两个模态。
这是通过执行一个前向传播来实现的,其中两个跨模态分支的条件信号都被置空 (nullified),这等同于单模态的无条件估计。
具体来说,我们定义了音频和视频的无条件估计(不含跨模态交互)为 uθv 和 uθa,以及含跨模态交互的估计为 uθv,a。
然后,MA-CFG 对每个模态的公式为:
u^v=uθv+sv(uθv,a−uθv) u^a=uθa+sa(uθv,a−uθa)其中 sv 和 sa 分别是控制视频和音频模态指导强度的系数。
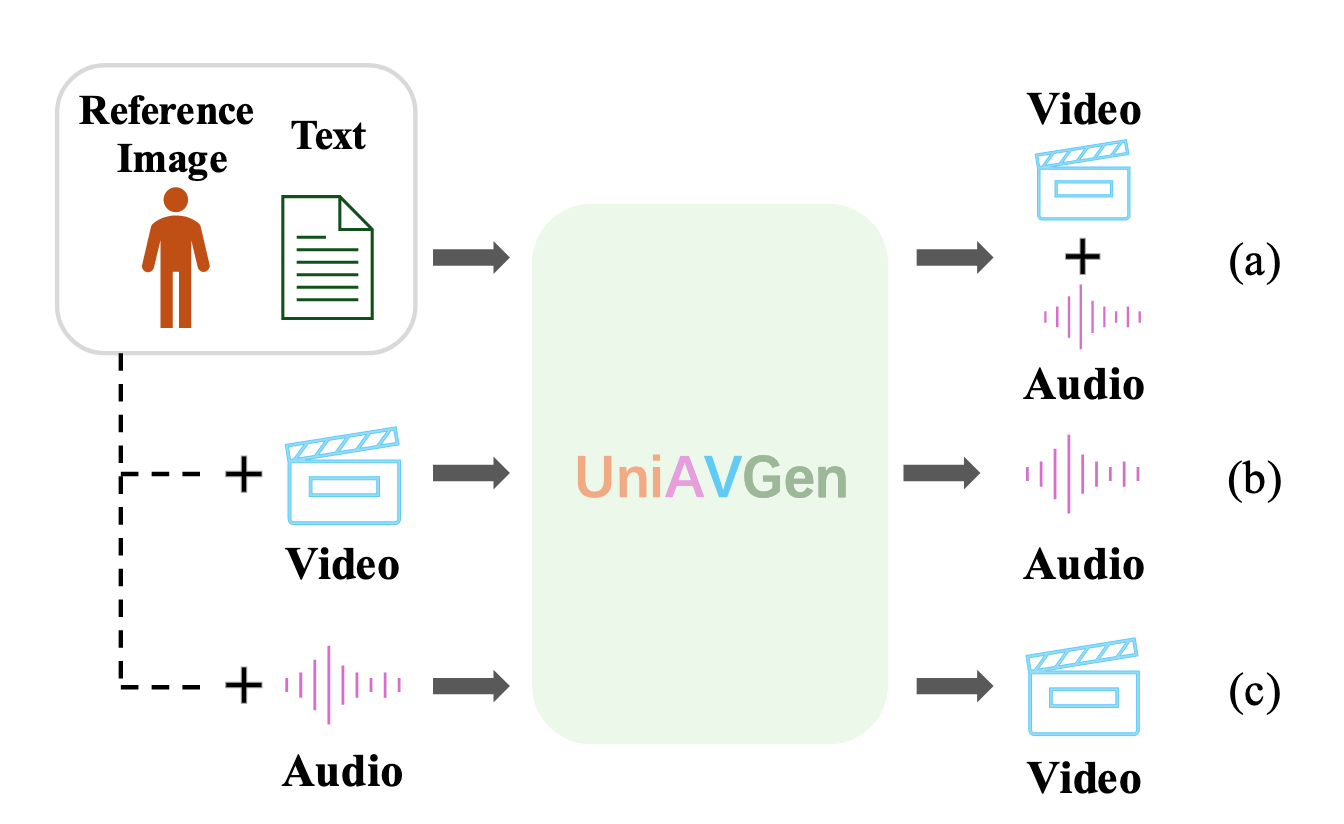
利用 UniAVGen 整体设计的对称性和灵活性,我们支持多种输入组合来处理不同的任务:
- 联合音视频生成 (Joint audio-video generation): 核心任务,仅接受文本和参考图像作为输入,生成对齐的音频和视频。
- 带参考音频的联合生成 (Joint generation with reference audio): 相比于 (1),它支持输入自定义的声音片段来控制说话者的音色一致性。值得注意的是,为了保持音色一致性,我们跳过了参考音频的跨模态交互。
- 联合音视频接续 (Joint audio-video continuation): 它基于给定的条件音频和条件视频执行连续生成。对于此任务,条件信息也参与跨模态交互,同时其特征保持不受交互影响,以保留时间连续性。
- 视频转音频配音 (Video-to-audio dubbing): 仅提供条件视频时,模型根据视频和文本生成对应的情感和表情对齐的音频。可以可选地提供参考音频来锚定音色,并且视频分支的参考图像用条件视频的第一帧填充。
- 音频驱动视频合成 (Audio-driven video synthesis): 仅提供条件音频时,模型根据音频和文本在视频分支中生成表情和运动对齐的视频。