
Table of Contents
TalkingHead 陆宇昕 Link to TalkingHead 陆宇昕
1. EMO: Emote Portrait Alive — Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions Link to 1. EMO: Emote Portrait Alive — Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
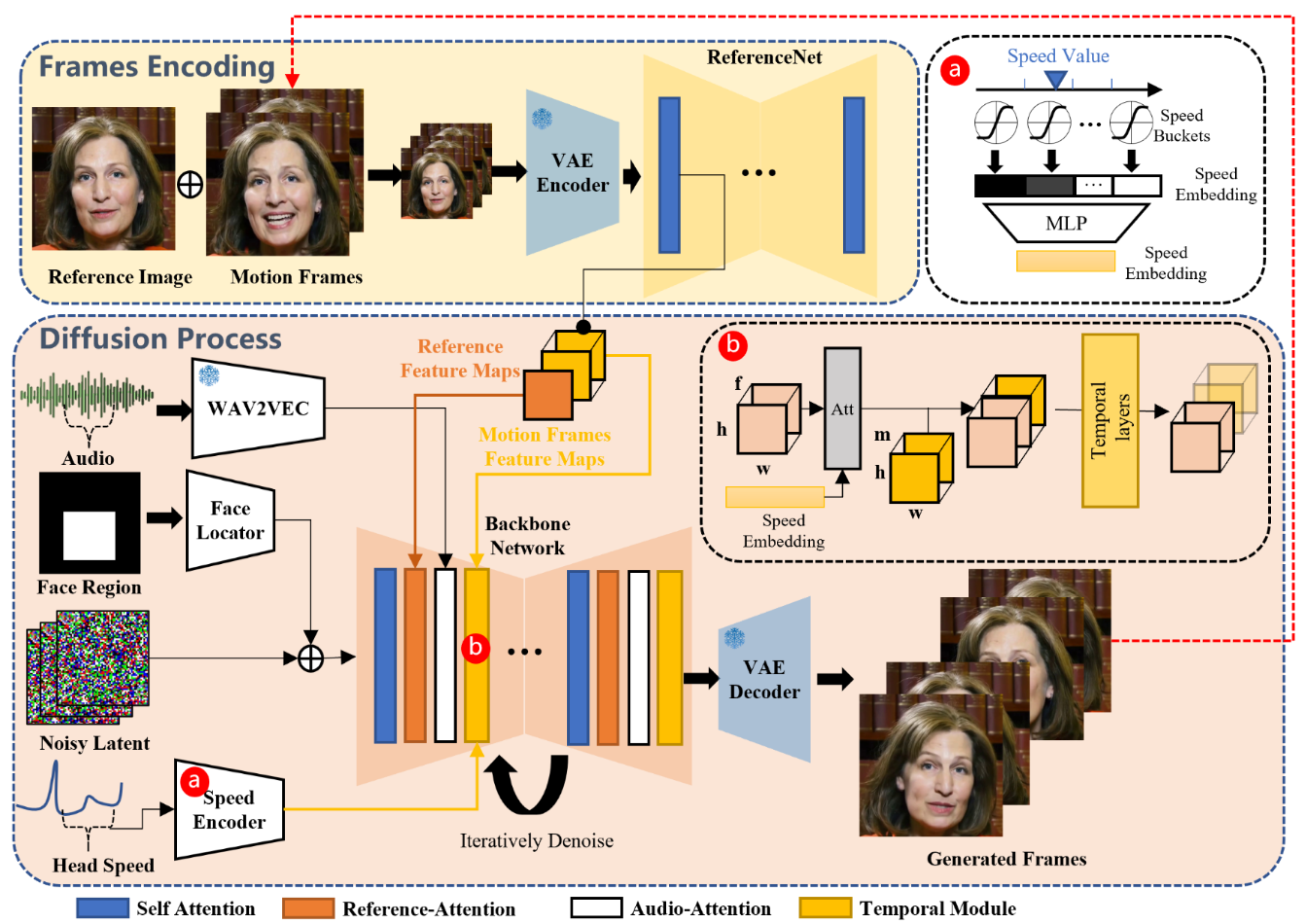
Audio Layer Link to Audio Layer
每一帧的音频输入要拼接邻近帧
ReferenceNet Link to ReferenceNet
类似于ControlNet中的操作,再用一个Unet提取条件
Temporal Modules Link to Temporal Modules
借鉴 AnimateDiff 的思想,在帧特征中引入了自注意力时序层,以捕获视频的动态内容。
输入特征图 重构为 ,其中f为帧数。注意力跨时间维度f进行,以建模帧间动态。
为保证长视频的连续性,引入运动帧:将前一个片段的最后n帧作为输入,以增强跨片段一致性。这些运动帧通过 ReferenceNet 提取特征,在去噪时与主干特征融合,从而保证生成视频片段的平滑衔接。
==运动帧:误差累积==
Face Locator 和 Speed Layers Link to Face Locator 和 Speed Layers
虽然时序模块保证了视频片段内部的连续性,但独立生成过程会导致片段之间的运动不一致。先前工作难以捕捉完整的面部动态,采用信号:
- Face Locator:生成面部区域的 bounding box 掩码,并将其编码为特征,与潜变量融合,控制人脸位置。
- Speed Layers:考虑头部在第f帧的旋转速度, 将其量化为 d 个速度区间,并通过 MLP 编码为速度特征嵌入,再与时序特征融合。通过指定目标速度,可以同步角色头部在不同片段中的运动频率。
2. Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation Link to 2. Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
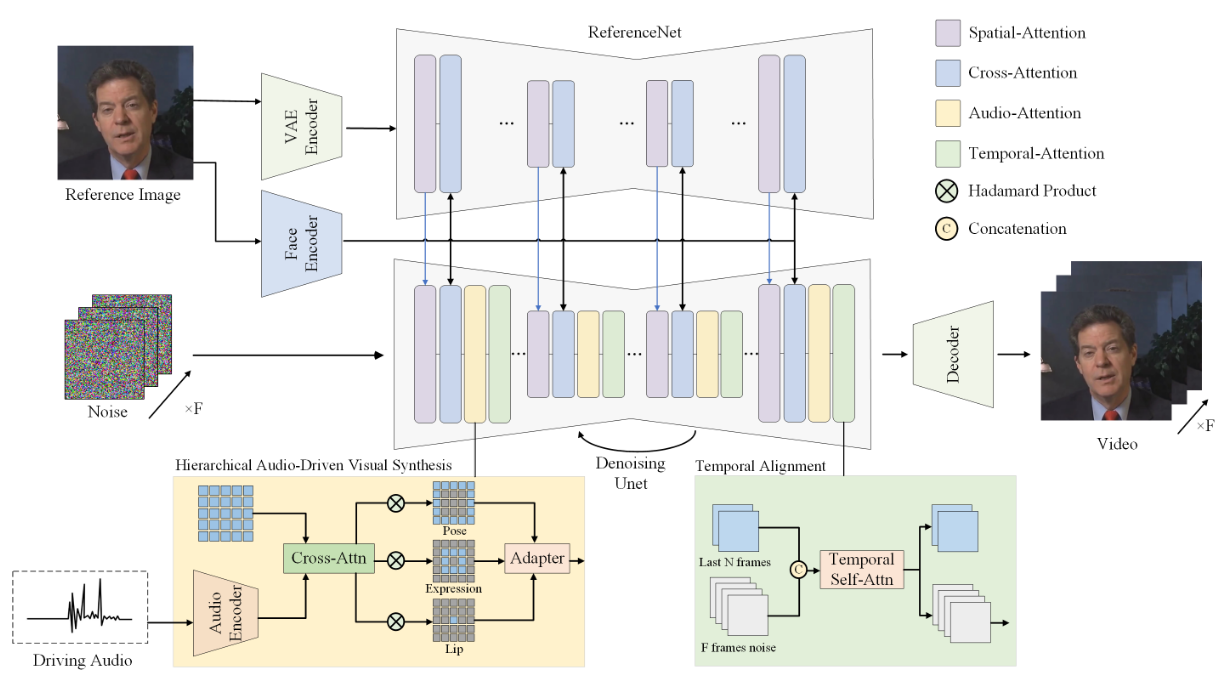
Face Embedding Link to Face Embedding
使用预训练的人脸编码器提取身份特征
Audio Embedding Link to Audio Embedding
wav2vec作为音频特征编码器
将 wav2vec 网络最后 12 层的音频embedding拼接
考虑到序列音频数据的上下文影响,我们提取对应于S帧的5秒音频片段
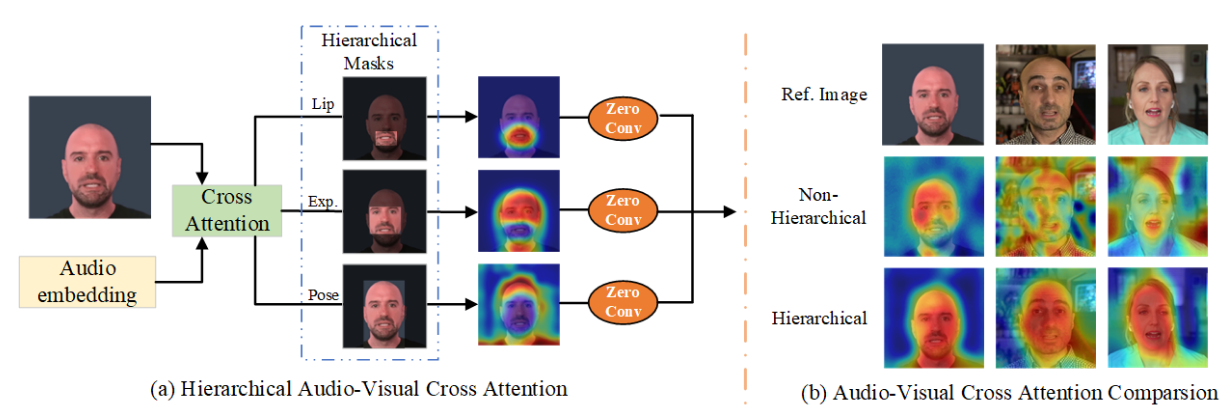
分层音频-视觉交叉注意力 Link to 分层音频-视觉交叉注意力
先预处理得到唇部、表情和姿态区域的掩码。
具体地,我们使用 MediaPipe 工具箱预测人脸图像 的关键点,包括嘴唇和表情的多个关键点。基于这些关键点的包围框生成掩码 :
其中 BoundingBox 表示所有关键点的包围框。随后计算:
其中 表示 Hadamard 乘积。
也就是:
- 唇部保留唇部
- 表情是把唇部挖去
- 姿势是把挖去了的唇部的表情删去
接着,我们在潜在表示和音频嵌入之间应用交叉注意力机制:
并利用掩码获得不同尺度的潜在表示:
最后,为了有效融合这些输出,我们引入了一个自适应模块来处理分层音频引导。输出通过卷积层获得:
时间对齐 Link to 时间对齐
一组来自前一个推理步骤的帧(在实现中使用 2 帧)被指定为运动帧。这些运动帧与潜在噪声在时间维度上拼接,并在时间轴上进行操作。这种时间操作通过多个自注意力模块实现,每个模块负责处理视频帧序列中的时间依赖关系。
3. Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation Link to 3. Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
[2410.07718v2] Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
[fudan-generative-vision/hallo2: ICLR 2025] Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation
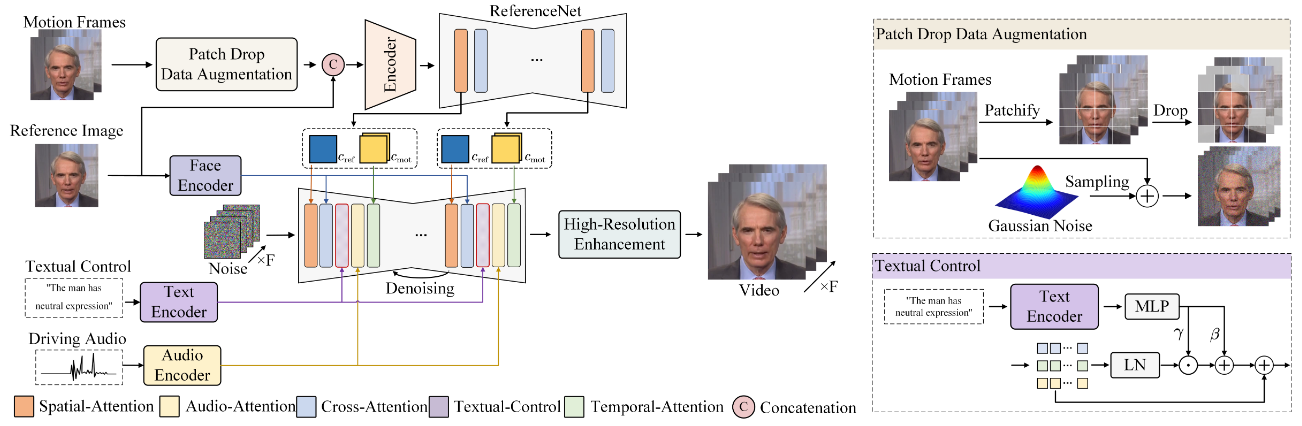
Patch Drop数据增强 Link to Patch Drop数据增强
对要推理的帧的前部分帧,每一帧都patchify为p*p块,并作随机mask
高分辨率增强 Link to 高分辨率增强
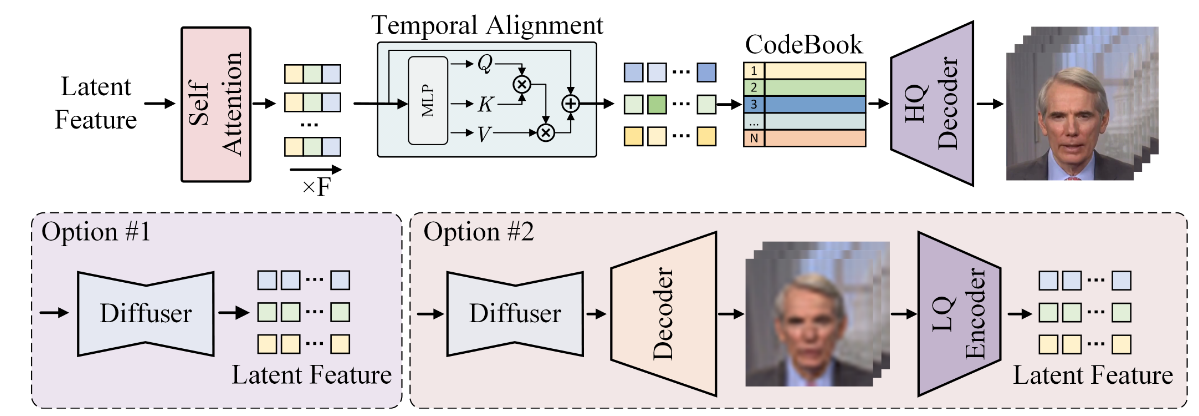
使用VQGAN的codebook压缩,在每个transformer块中既包含一个空间自注意力,也包含一个时间自注意力
空间注意力
- 每一帧内部通过自注意力来捕捉局部和整体的空间关系,保证单帧的细节质量。
时间对齐
- 在空间注意力之后,把每帧的表示重新 reshape 成时间序列,再做时间注意力。
- 这样模型能学到帧与帧之间的依赖关系,保证 表情、动作在帧序列中平滑过渡。
文本信息控制 Link to 文本信息控制
见图,AdaptiveLayerNrom
训练 Link to 训练
在一阶段,模型训练目标是生成视频帧,输入包括参考图像、驱动音频和目标视频帧。
冻结VAE 编码器和解码器,以及人脸图像编码器的参数。
优化过程重点在于 ReferenceNet 与去噪 U-Net 内部的空间交叉注意力模块,目标是提升模型的肖像视频生成能力。具体而言,从输入视频片段中随机选择一帧作为参考图像,相邻帧作为目标训练图像。同时引入运动模块,以提升模型的时间一致性和平滑性。
第二阶段,对运动帧应用 patch-drop 和高斯噪声增强,用于训练模型生成长时长视频,以保证时间一致性和平滑的运动过渡。
通过在条件集中引入受损运动帧,进一步建模时间动态,提升模型在长序列中捕捉运动连续性的能力。
同时,在该阶段引入文本提示,以实现基于文本的面部表情与动作的精确调控。对于超分辨率模块,则优化 VAE 编码器的参数,专注于码本预测权重的学习。Transformer 架构中的时间对齐机制则确保跨帧输出的一致性和高质量表现,从而提升高分辨率细节的时间一致性。
4. EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions Link to 4. EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions
https://arxiv.org/abs/2407.08136
https://github.com/antgroup/echomimic
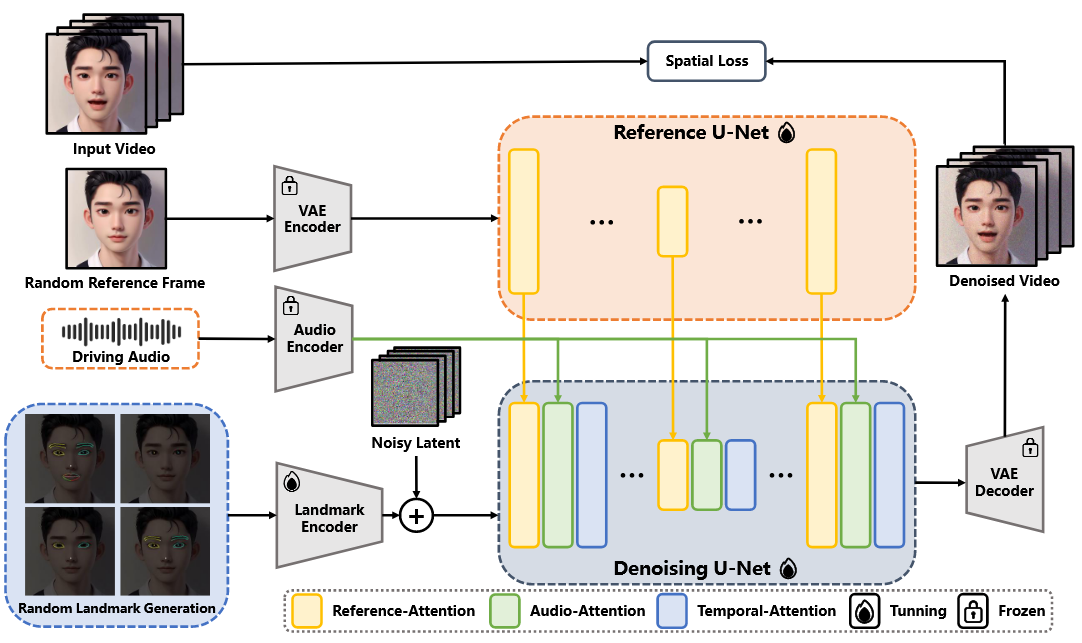
Reference U-Net Link to Reference U-Net
在 Reference U-Net 的 Transformer 模块中,使用自注意力机制提取参考图像特征,这些特征作为 key 和 value 输入到去噪 U-Net 的 Reference-Attention 层中。Reference U-Net 仅用于编码参考图像,不引入噪声,扩散过程中只执行一次前向传播。
为了避免引入无关信息,向交叉注意力层输入一个空文本占位符。这样可以确保参考图像特征的准确捕获与无缝整合,从而提升生成结果的保真度。
Audio Encoder Link to Audio Encoder
将输入音频序列的特征拼接,生成对应帧的音频表示。由于角色的动作可能受到前后音频片段的影响,因此在生成每一帧时拼接邻近帧的音频特征以引入上下文。随后,这些音频特征输入到去噪 U-Net 的udio-Attention 层,与 Reference-Attention 的输出进行交叉注意力计算,从而将语音信息融入生成过程。这确保了生成的人物动作能够与语音细节精确同步,增强了生成结果的自然性和表现力。
Landmark Encoder Link to Landmark Encoder
一个轻量级卷积模型,将人脸关键点图像编码为与潜在空间维度匹配的特征表示。
然后,这些特征通过逐元素相加的方式与多帧潜在表示结合,再输入到去噪 U-Net。
保证了空间结构信息的准确整合,从而提升生成序列在解剖结构和运动上的一致性与保真度。
Temporal Attention 层 Link to Temporal Attention 层
,
其中, 表示 batch 大小, 表示帧数, 表示特征维度, 表示图像空间大小。
通过调整维度:,
可以在时间维度上应用自注意力机制以捕捉帧间依赖关系。
Spatial Loss Link to Spatial Loss
由于潜在空间的分辨率(例如 ,对应 的图像)过低,难以捕捉细节特征,因此我们引入time-step感知的spatial loss,以直接在像素空间中学习人脸结构。
预测潜在表示 首先通过采样器映射为 ,再通过 VAE 解码器生成预测图像。最终,均方误差(MSE)损失在预测图像 和真实图像 之间计算。同时引入LPIPS 损失来进一步约束细节。由于在较大时间步 时难以收敛,我们设计了一个基于时间步的权重函数来降低其影响。
目标函数定义为:
其中:
这种设计通过逐步减少大时间步的权重,使模型能够更好地学习人脸细节。
5. EMO2: End-Effector Guided Audio-Driven Avatar Video Generation Link to 5. EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
https://arxiv.org/abs/2501.10687
部分身体动作生成 Link to 部分身体动作生成
给定音频输入,EMO2并非像 EMO 那样直接作用于像素,而是设计了一个部分身体运动生成模型,作为中间驱动信号,用于生成视频中的伴语手势。
基本原理是:人体运动本身具有自然性,可以通过3D模型表示为预定义手势。
仅通过手部运动就足以刻画上半身的运动,因为其他身体部位的动作可以通过逆运动学推导得到。
将手部与其他身体部位的控制解耦,可以增强动作的表现力和强度。
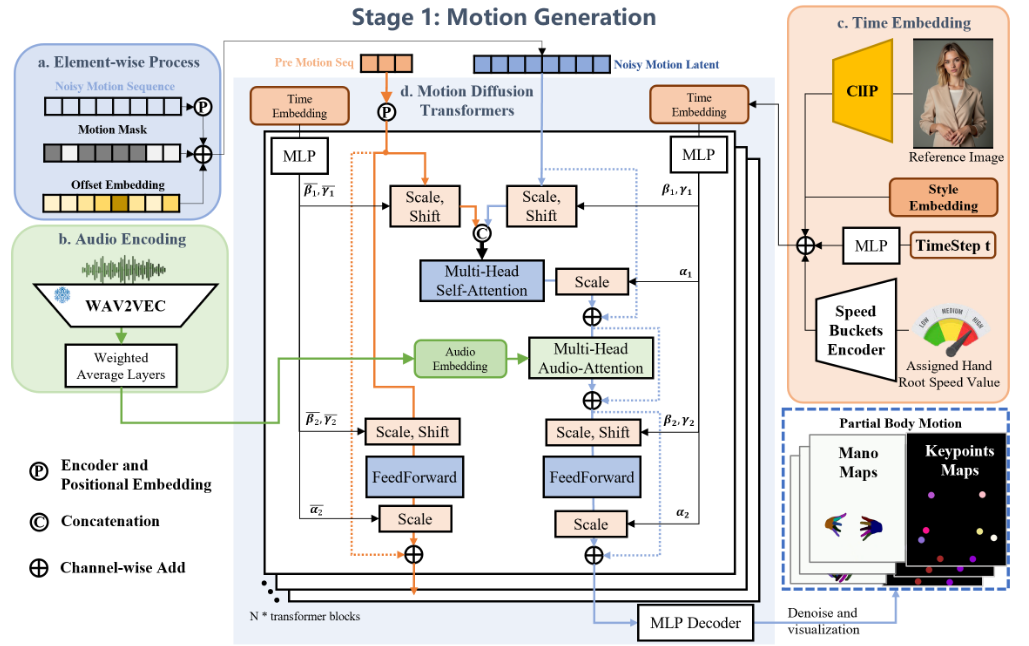
手部运动的生成 Link to 手部运动的生成
为了确保片段之间的平滑衔接,我们将前一个片段的最后几帧运动序列拼接到当前运动序列中。音频特征由 Wav2vec提取。除手部运动外,还引入上半身的关键点作为弱监督信号。
手部运动掩码与手部偏移 Link to 手部运动掩码与手部偏移
在训练数据集中,部分帧的 MANO 手部注释可能缺失或不准确(例如手被遮挡)。
为了减轻这些情况的影响,引入运动掩码,将无效的手部参数帧标记并添加到带噪运动潜变量中。
此外,加入偏移嵌入,描述身体相对位置与旋转的差异,用以分离数据集中手部与身体姿态之间的耦合。
风格、速度与参考图像嵌入 Link to 风格、速度与参考图像嵌入
为了生成不同风格的手部运动(如唱歌、演讲或舞蹈),在时间步嵌入中加入风格嵌入。
此外,将手部运动划分为不同速度区间,每个区间设有中心和半径,并根据距离编码具体的速度值。这样,时间步嵌入中会额外包含手部速度控制信号。
实践中,发现用手部平移的方差表示运动幅度(而非速度),能带来更好的控制效果。可选地,还可以引入参考图像信息,例如角色手持物体(吉他、话筒等)的情况。为此,采用 CLIP 提取参考图像的嵌入,并将其加入时间步,从而使生成的手部运动更契合参考场景
Co-Speech Video生成 Link to Co-Speech Video生成
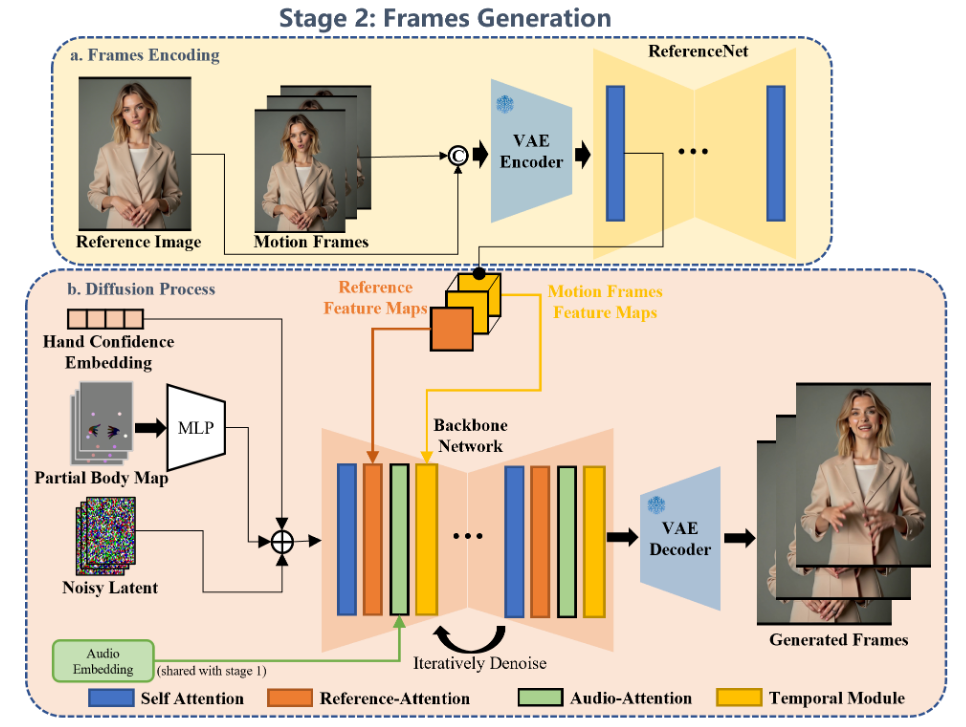
手部运动控制 Link to 手部运动控制
第一阶段生成的 MANO 图显式指导角色运动,提供关于手部形状、大小和姿态的控制信号。
但由于 MANO 标注在训练数据中存在误差(如遮挡或模糊),可能导致生成手部效果不佳。
为此,引入手部置信度控制,利用 MANO 检测的置信分数生成可训练嵌入,并在推理时赋予高置信帧更高的权重,以生成更清晰、结构合理的手部。
关键点引导控制 Link to 关键点引导控制
最初只使用手部信号控制,但观察到大幅度手部动作常导致躯干失真,因此引入了上肢和腿部的 2D 关键点作为补充。虽然这些 2D 关键点不能完全描述 3D 身体结构(如手臂长度),但仍能有效指示关节运动趋势。为增强其作用,我们在训练第二阶段模型时,对关键点序列施加大核中值滤波,使其有意与身体关节错位,从而为生成的身体动作提供一定自由度,促进更具表现力的视频生成。
姿态判别器 Link to 姿态判别器
为提升角色身体结构一致性,我们在训练时引入姿态判别器。每个训练时间步,模型会采样预测输出,并将其输入姿态判别器,预测身体关键点和肢体热力图。判别器损失定义为:
其中 H 表示真实热力图。该损失在去噪过程中被引入,以提升身体姿态生成质量。姿态判别器基于 ResNet并在潜在空间预训练。
6. Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Video Diffusion Transformer Link to 6. Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Video Diffusion Transformer
https://arxiv.org/abs/2412.00733
https://github.com/fudan-generative-vision/hallo3
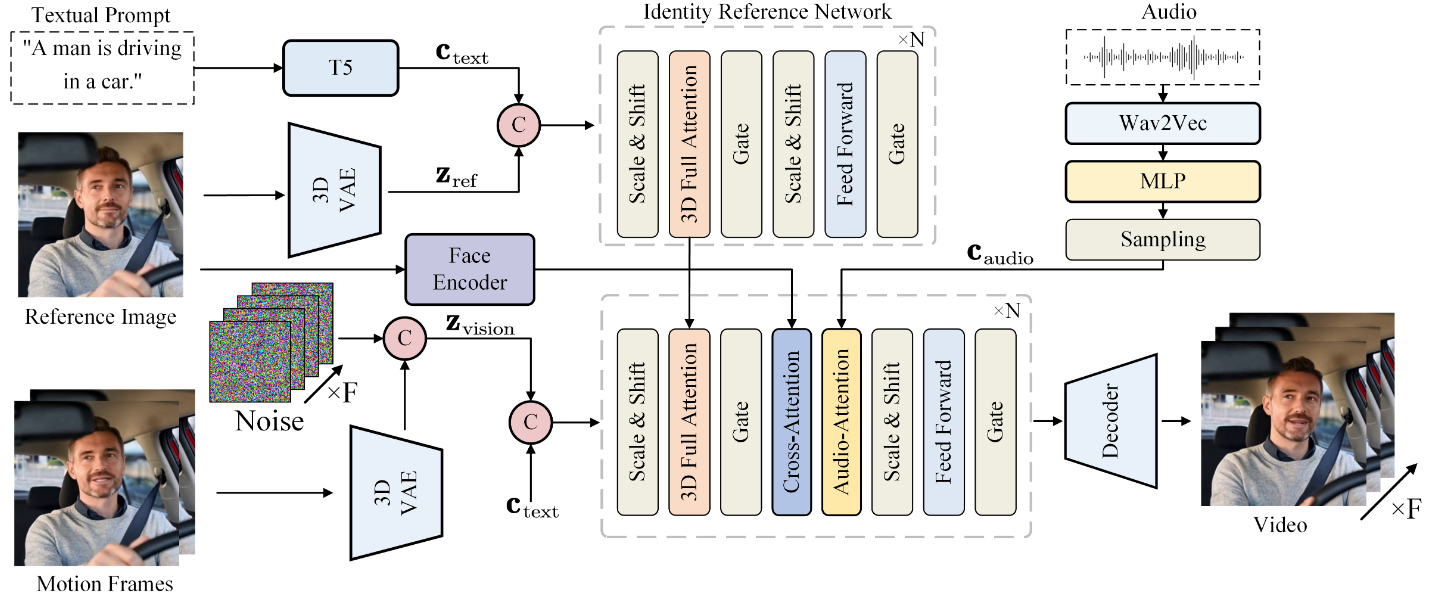
Transformer 扩散网络 Link to Transformer 扩散网络
基线网络 CogVideoX 模型作为本文 DiT 的基础架构
3D VAE 处理视频,T5编码文本,然后拼接
AdaLN保证视觉和语义的对齐
3D VAE还原视频
同时使用3D RoPE建立时序信息
实测 adaLN 在简单场景下效果良好,但在复杂语义条件(如序列化语音音频)下效果有限。
音频驱动的 Transformer 扩散 Link to 音频驱动的 Transformer 扩散
语音音频嵌入 们将 wav2vec 网络最后 12 层生成的音频嵌入拼接,从而得到层次化的语义表示,能够捕捉语音的多层次特征,尤其突出语音学成分(如发音、语调和韵律),这些信号对角色生成至关重要。
为了将音频嵌入转化为逐帧表示,我们通过三个线性变换层处理,公式为:
其中 为线性变换函数。该方法确保得到的帧级表示能够有效封装细粒度的音频特征。
语音音频条件
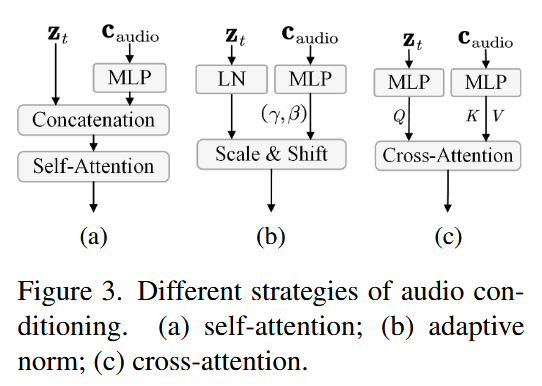
本文探索了三种融合策略:自注意力、自适应归一化和跨注意力。实验表明,跨注意力策略在模型中表现最佳。
具体做法是:在去噪网络的每个面部注意力层后插入音频注意力层,使潜编码与音频嵌入交互,从而增强生成效果。跨注意力计算公式为:
该方法充分利用了音频嵌入的条件信息,提高了生成结果的连贯性与相关性,使模型能够更好地捕捉驱动角色生成的语音细节。
身份一致性 Transformer 扩散 Link to 身份一致性 Transformer 扩散
身份参考网络
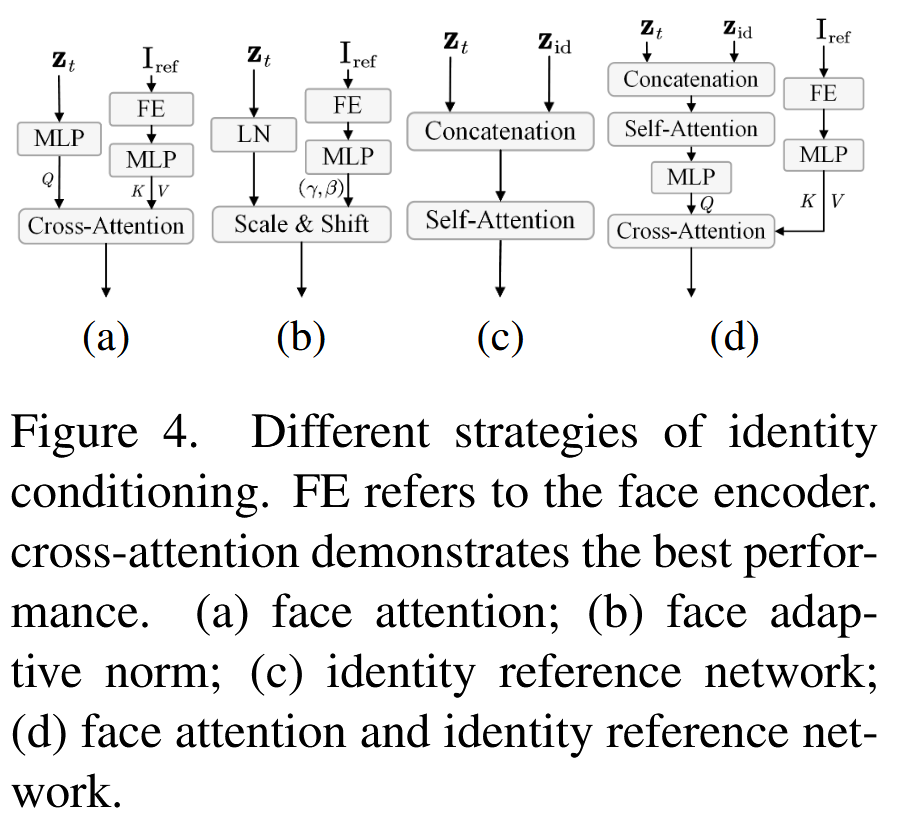
探索了四种外观条件策略:
- 人脸注意力:通过人脸编码器提取身份特征,并结合跨注意力模块。
- 人脸自适应归一化:在人脸编码器中集成自适应层归一化。
- 身份参考网络:使用三维 VAE 捕捉身份特征,并结合多层 Transformer。
- 人脸注意力 + 身份参考网络:结合人脸编码器与三维 VAE 的特征,并通过自注意力与跨注意力共同作用。
实验表明,第四种方案效果最佳。
实现细节 参考图像作为单帧输入三维 VAE,得到潜特征,再经过 42 层 Transformer 参考网络处理。这些特征被注入去噪网络的对应层,用于增强身份一致性:
其中 为第 t 步的潜表示。由于参考网络与去噪网络共享相同的三维 VAE 和 Transformer 架构,二者的特征具有一致性,从而实现长时序视频中稳定的身份保持。
时序运动帧 为生成长视频,引入“运动帧”,即之前生成视频的最后 n 帧。通过三维 VAE 获取这些帧的潜特征,再与新的高斯噪声拼接,作为下一次生成的条件输入,从而实现时序一致的长视频生成。
训练 Link to 训练
训练过程分为两个阶段:
- 身份一致性训练:三维 VAE 与人脸编码器的参数固定,参考网络和去噪网络的 Transformer 模块可更新。输入为参考图像和文本提示,输出为 49 帧视频序列。
- 音频驱动训练:在去噪网络的每个 Transformer 模块中加入音频注意力层,仅更新这些模块参数,其他部分保持不变。输入为参考图像、音频和文本提示,输出同样为 49 帧视频。
7. Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency Link to 7. Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
https://arxiv.org/abs/2409.02634
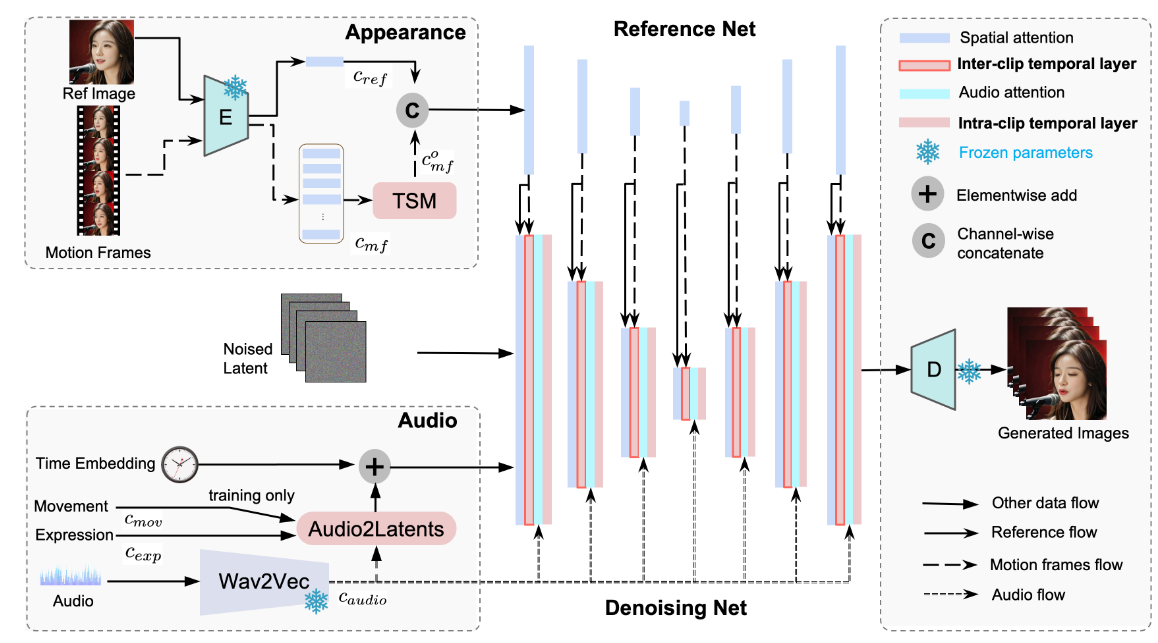
Inter/Intra-CLIP Temporal Module Link to Inter/Intra-CLIP Temporal Module
Loopy 采用 两个时间注意力层:跨片段时间层和片段内时间层。
- 跨片段时间层:建模运动帧潜变量和噪声潜变量之间的跨片段关系。
- 片段内时间层:关注当前片段内噪声潜变量的时间关系。
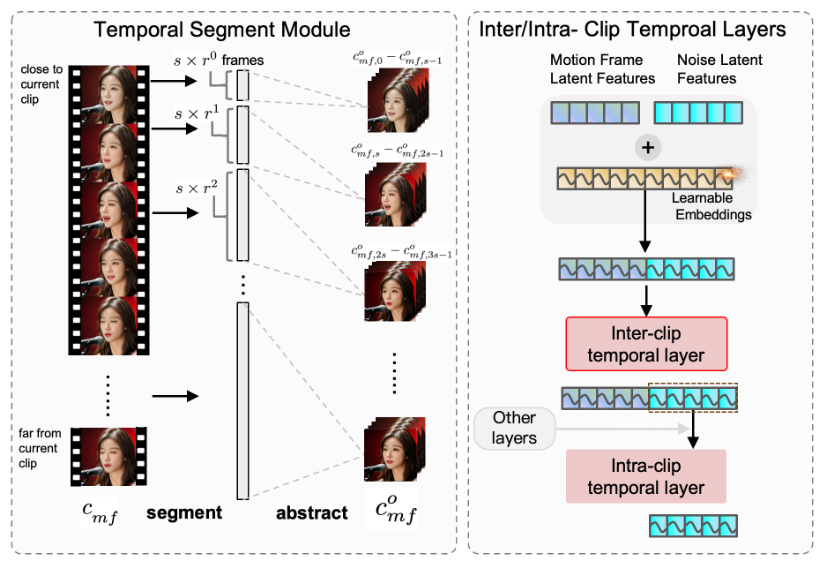
由于跨片段时间层的设计,Loopy 能够更好地建模片段间的运动关系。为了进一步增强该能力,我们在运动帧进入参考网络之前引入 时间分段模块。该模块不仅扩展了跨片段时间层的时间范围,还能基于当前片段与前序片段的距离提取不同粒度的时间信息(如图 3 所示)。
时间分段模块将原始运动帧划分为多个片段,并从每个片段中提取代表帧以抽象该片段。经过抽象的运动帧被重新组合为新的运动帧潜变量 ,用于后续的跨片段时间计算。
在分段过程中,引入两个超参数:
- 步长 s:表示每个片段中的抽象运动帧数量;
- 扩展比 r:用于计算每个片段的原始运动帧数量。
例如,若s=4、r=2,则第一个片段包含 4 帧,第二个片段包含 8 帧,第三个片段包含 16 帧。分段后采用均匀采样。
这种方式显著扩展了跨片段时间层的覆盖范围,并在计算复杂度可控的情况下,更好地捕捉长时依赖的动作风格,生成更自然的动作。
音频条件模块 Link to 音频条件模块
将 wav2vec 各层的隐藏状态拼接,以获得多尺度音频特征。对每一视频帧,将前后各两帧的音频特征拼接,得到一个 5 帧范围的音频特征,作为该帧的音频嵌入。
在每个残差块中,使用交叉注意力机制:噪声潜变量作为查询,音频嵌入作为键和值,计算加权后的音频特征。该特征随后被加入跨片段时间层生成的噪声潜变量中,从而得到新的噪声潜变量,形成初步的音频条件。
Audio-to-Latents 模块 Link to Audio-to-Latents 模块
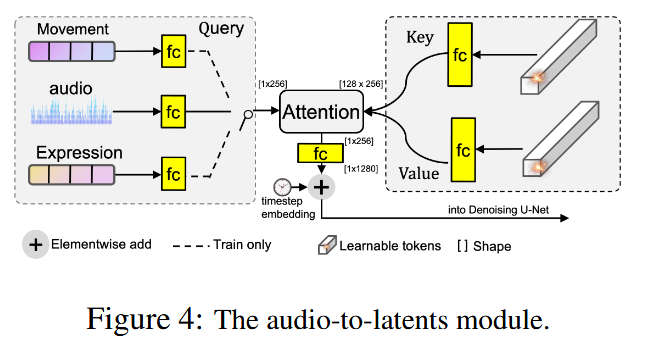
引入audio-to-latents 模块,以增强音频对人像动作的影响。该模块在训练时接收多种输入,包括:
- 头部运动方差、表情方差(与人像动作强相关);
- 音频特征(相关性较弱)。
这些条件被映射到共享的运动潜变量空间,替代原始条件参与计算。
具体实现方式如下:
- 每个输入条件通过全连接层映射为查询特征;
- 维护一组可学习嵌入(128 个),作为键和值,进行注意力计算;
- 全连接层将 QKV 特征统一到 256 通道;
- 生成的值特征(即运动潜变量)进一步扩展到 1280 通道,并加入时间步嵌入。
在训练过程中,audio-to-latents 模块以相等概率随机选择一种输入条件(音频嵌入、头部运动方差或表情方差)。在测试阶段,仅输入音频特征来生成运动潜变量。
这种机制使音频能够通过共享潜变量空间,更准确地影响动作生成,同时避免对无关区域的过度关注。实验表明,表情与动作也能够通过运动潜变量影响视频合成。
训练 Link to 训练
条件掩码与 Dropout Link to 条件掩码与 Dropout
在 Loopy 框架中,涉及多种条件,包括参考图像 、音频特征 、前序帧运动帧 ,以及表示音频和面部运动条件的潜变量。
为了更好地学习每种条件所包含的独特信息,在训练过程中为这些条件设计了不同的掩码策略。在训练时, 和运动潜变量会以 10% 的概率被掩码为全零特征。对于 和 ,我们设计了特定的 dropout 与掩码策略,因为它们包含大量重叠信息。特别是 相比 更接近当前片段,提供了更具时效性的外观信息,容易导致模型过度依赖运动帧而忽视参考图像。
为了解决这个问题,为 设置了 15% 的丢弃概率,这意味着去噪 U-Net 在进行空间注意力计算时不会拼接参考网络的特征。如果 被丢弃,运动帧也会被丢弃,即去噪 U-Net 不会拼接来自参考网络的特征。除此之外,运动帧还有 40% 的独立概率被掩码为全零特征。
多阶段训练 Link to 多阶段训练
借鉴 AnimateAnyone 和 EMO,采用 两阶段训练流程。
第一阶段:模型在没有时间层和音频条件模块的情况下训练。此时,输入为目标单帧图像的噪声潜变量和参考图像潜变量,任务是学习图像层级的姿态变化。
第二阶段:模型以第一阶段训练得到的参考网络与去噪 U-Net 为初始化,再加入跨片段/片段内时间模块以及音频条件模块进行完整训练,最终得到完整模型。
8. Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation Link to 8. Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation
https://arxiv.org/abs/2505.23525
偏好数据集构建 Link to 偏好数据集构建
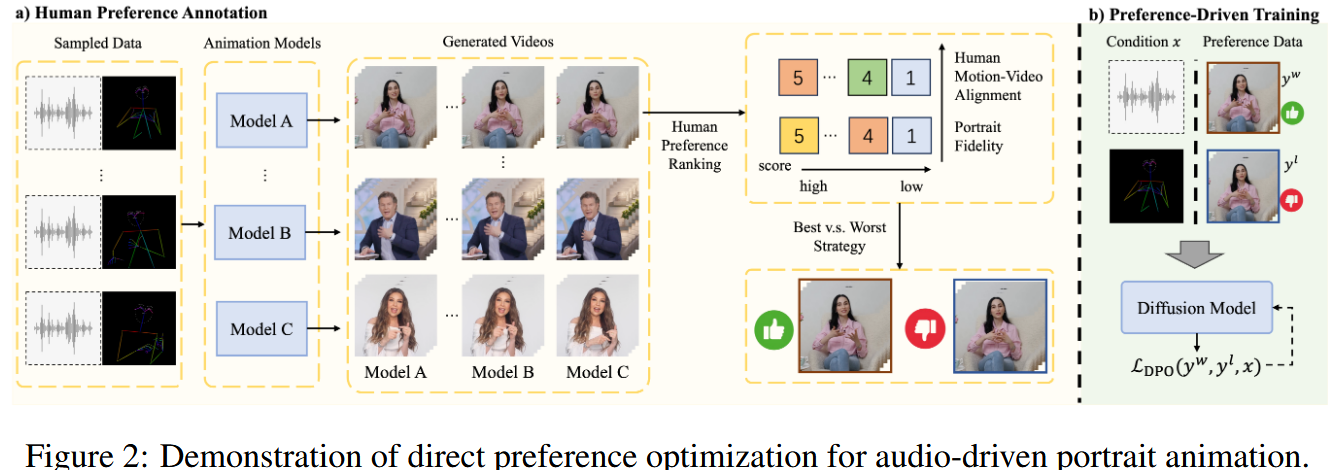
为了为人像动画中的直接偏好优化建立一个可靠的基础,我们构建了一个多模态数据集,捕捉了人类偏好在两个关键维度上的表现:(1) 运动-视频对齐,(2) 人像保真度。
偏好度量 Link to 偏好度量
运动-视频对齐和人像保真度是评价合成人像动画的两个关键指标。运动-视频对齐衡量生成的动画与人类动作条件之间的时间一致性,尤其强调了嘴唇同步(与音频输入匹配)和身体动作的节奏匹配。人像保真度评估生成内容的感知质量,特别强调语义一致性(如情绪传达:喜悦、愤怒、惊讶)以及整体自然性和逼真度。这些指标共同确保了动态人像生成系统在感知精度和人类可接受性上的平衡。
偏好数据集构建 Link to 偏好数据集构建
直接偏好优化将人类偏好对齐视为一个策略优化问题,利用成对偏好数据:
其中 是被偏好的样本, 是被舍弃的样本。我们通过标注员评估生成样本,并采用“最佳与最差”选择策略来得到最终的偏好数据集。
对于每段音频,用五种方法(GAN、UNet、DiT 等)生成候选视频,然后由人工标注员从两个维度(运动-视频对齐与人像保真度)进行 5 分制打分,并将其合成为复合奖励:
偏好优化 Link to 偏好优化
我们将直接偏好优化引入扩散模型。设生成策略为 ,参考策略为 。优化目标为:
其中 是 sigmoid 函数, 控制参考偏离程度。该目标隐式定义了奖励函数:
在 DiT 模型中,基于流匹配的 DPO 损失为:
其中 分别表示偏好样本与非偏好样本的速度场。通过最小化该损失,预测的速度场 向人类偏好对齐,并远离劣质样本。
统一的时间运动调制 Link to 统一的时间运动调制
现有的基于 DiT 的扩散模型在将多模态运动信号(如语音音频和骨架序列)与压缩的视频潜在表示对齐时,容易因时间分辨率不匹配和维度不兼容而遇到困难。提出了一种时间重塑策略,通过时间维度匹配和比例特征扩展,将运动条件与视频潜在表示对齐,从而保持运动细节。
潜在视频表示 Link to 潜在视频表示
原始视频 经由预训练的 3D VAE 编码为压缩的潜在表示
其中 ,,。
人体运动条件 Link to 人体运动条件
处理两种运动模态:
- 音频驱动的面部运动:原始语音信号 转换为声学特征
- 骨架驱动的肢体运动:关键点 ,通过卷积网络得到运动描述符
时间重塑与融合 Link to 时间重塑与融合
为解决时间分辨率不匹配问题,我们采用特征重分布策略。对每个运动条件 ,重塑时间轴:
其中 。然后通过线性投影得到:
最后通过跨注意力机制进行融合:
其中 ,,。
DPO 增强的扩散网络 Link to DPO 增强的扩散网络
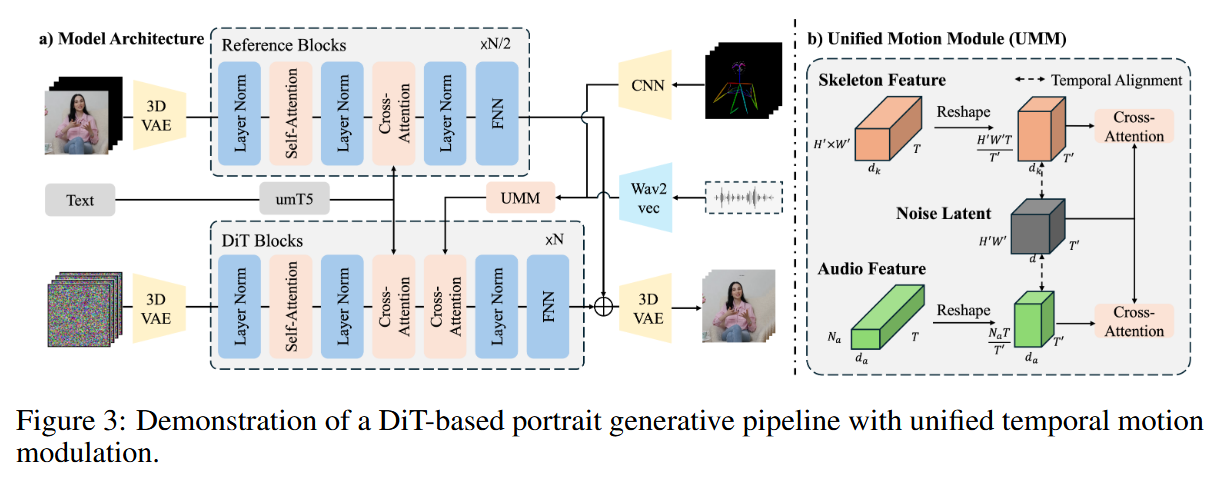
在 UNet 和 DiT 两种扩散架构中验证了偏好数据集和 DPO 框架。统一的时间运动调制策略主要应用于 DiT 架构。
- UNet 架构:采用 EMO、Hallo、EchoMimic-v2 等设计原则,基于 Stable Diffusion v1.5 作为主干。并行的 ReferenceNet 结构保持视觉一致性,同时通过跨注意力引入语音特征。
- DiT 架构:采用 Wan2.1 框架作为主干,使用 3D VAE 进行时空压缩。Transformer 模块将视频展开为 token 序列,块内包含自注意力、跨注意力(用于条件输入)、时间步嵌入等。去噪过程基于流匹配原理,构建最优传输路径的条件概率流,直接回归速度场。这使得噪声分布到数据分布之间的变换可通过确6定性的 ODE 形式来实现。
训练 Link to 训练
训练协议适应了 UNet 和 DiT 主干网络之间的架构差异,同时保持了偏好优化的一致性。
对于基于 UNet 的扩散模型,我们采用预训练的 Hallo 人像模型,并通过直接偏好优化进行微调。DPO 目标函数 通过在 UNet 参数上的梯度更新来优化去噪轨迹,使其与人类偏好判断保持一致。
对于 DiT 架构,训练遵循分阶段的方法,以确保多模态条件的稳定集成。阶段一侧重于音频驱动的合成,此时参数更新仅限于统一运动模块中的跨注意力层,而 3D VAE 和去噪器模块保持冻结。阶段二引入骨架引导,通过扩展运动模型以处理关节运动学,仅更新新引入的骨架跨注意力参数,同时保持冻结的 3D VAE 和去噪器块权重。这两个阶段均利用流匹配来回归速度场,从而编码时空动态特征。最后,我们应用 DPO 训练来调整去噪策略,通过对比梯度更新,优先优化人类偏好的运动模式和视觉质量,同时保持模型的时间一致性。
9. SkyReels-A1: Expressive Portrait Animation in Video Diffusion Transformers Link to 9. SkyReels-A1: Expressive Portrait Animation in Video Diffusion Transformers
https://arxiv.org/abs/2502.10841
https://github.com/SkyworkAI/SkyReels-A1
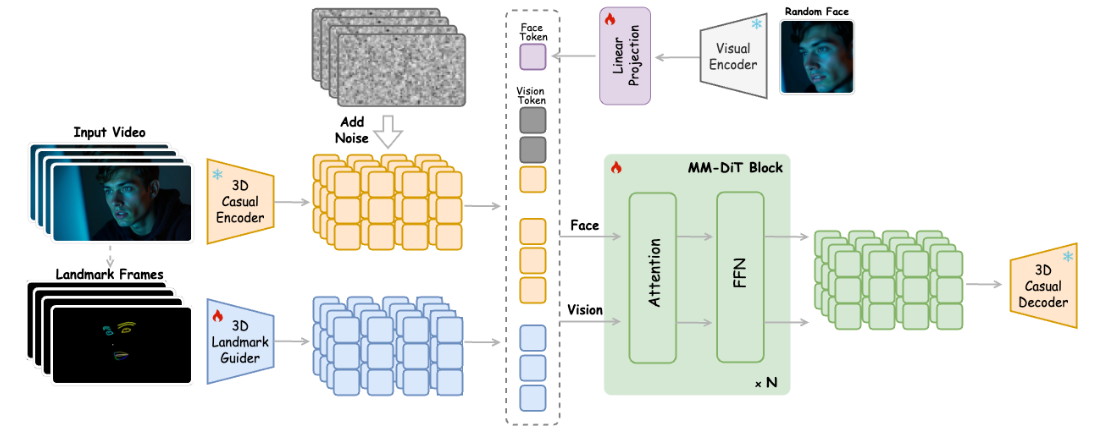
Expression-Aware Landmark Link to Expression-Aware Landmark
现有基于扩散的方法主要使用2D关键点作为运动表示进行训练。
局限:推理过程中依赖 2D 关键点,往往会导致目标表情与参考人像之间的不对齐,表现为表情不匹配和身份泄漏伪影。
而利用 MediaPipe 等工具从视频序列中提取3关键点的方法,虽然能一定程度上解决问题,但在捕捉非正面角度和极端表情下的细粒度动态时仍然不足。
提出了 3D Facial Expressions 框架,引入神经渲染模块以提升重建面部表情的准确性和真实感。
不同于依赖可微分渲染的方法,我们的方式通过神经渲染机制替代该组件,从而更高效地学习和泛化多样化的面部表情。
这一架构能够提取高精度的 3D 关键点,捕捉细腻的运动细节和复杂的表情动态。
3D Landmark Guider Link to 3D Landmark Guider
为了确保驱动信号与输入视频潜表示之间的时空一致性,提出了 时空对齐关键点引导模块。其核心由三维因果编码器组成,用于捕获驱动信号的运动表示。通过精调,该模块能有效对齐驱动信号与视频潜变量,确保生成结果的动作连贯性。
该模块通过将驱动信号直接投影到共享潜在空间,并与视频潜变量对齐,实现同步的空间和时间动态。进一步的精细调整过程还能捕捉复杂运动模式,提升动作迁移的真实性与保真度。这不仅确保了姿态对齐,还能在生成视频中保持动作一致性与身份稳定性,从而生成高质量、稳定的动画。
Facial Image-Text Alignment Module Link to Facial Image-Text Alignment Module
借鉴 CogVideoX 的设计,旨在通过在人脸图像和视频输入阶段拼接双重嵌入来提升表情生成过程中的身份一致性。这种方式不仅增强了身份保持,还使预训练模型的能力能够无缝迁移。
引入一个轻量级的可学习映射模块,通过多层感知机将身份特征映射到文本特征空间:
其中 是由视觉编码器 提取的身份嵌入。由于能捕捉到详细的面部特征,而视觉嵌入包含更广泛的上下文(如光照和遮挡),两者的结合提升了生成结果中面部特征的准确性。人脸图像-文本对齐模块则进一步增强信息融合,同时保持模型的高效性。
训练 Link to 训练
多阶段
运动驱动训练 Link to 运动驱动训练
在这一阶段,我们的目标是将运动条件引入视频生成过程。运动驱动的视频输入通过一个 三维关键点引导模块 处理,该模块由预训练的三维因果编码器初始化,并在此阶段保持冻结不变。为了有效融合基于关键点的运动信息并保持 IT2V架构 的完整性,提取的关键点潜在表示会与噪声输入拼接。模型对关键点特定变化的适应是通过仅训练 PatchEmbedding 模块内的卷积层 来实现的,从而确保系统在保持 IT2V 核心功能的同时精细化运动表示。
身份保持训练 Link to 身份保持训练
在随后的阶段,训练重点转向增强动画人像中的身份一致性。虽然文本条件不是人像动画所必需的,但保留文本处理分支,以利用预训练模型的能力。面部特征通过CLIP 图像编码器 编码生成面部表示,然后通过一个可训练的线性映射投射到文本特征空间。值得注意的是,只有该投影层会进行优化,其他部分保持不变。这样的设计确保了动画人像在不同表情和动作序列中都能保持身份一致性。
多模块联合微调 Link to 多模块联合微调
在最后阶段,模型会联合优化 三维关键点引导器、DiT 模块和线性投影层,从而提升动画的精细程度和高保真度。该阶段进一步增强了模型在不同体型与动作场景下的泛化能力,使其能够应对范围更广的表情和动态动作,并保持更高的真实感。
面部感知损失(Face-Aware Loss) Link to 面部感知损失(Face-Aware Loss)
生成视频的流畅性在很大程度上依赖于动态区域(如人脸)的空间一致性和真实感。
引入了面部感知损失,使模型优先关注高运动区域。
在实现上,我们使用 作为光流估计器 ,以高效准确地估计光流。然后计算平均光流值 ,方法是简单地对光流值 取平均。接着,以 为阈值生成二值掩码 。具体来说,当光流幅度超过 时,将对应位置的掩码值设为 1,否则设为 0。于是,前景光流的平均值 可表示为:
其中, 表示像素 的前景光流, 表示前景像素的数量。
接着我们对前景光流进行归一化,并计算光流掩码:
其中函数 将数值限制在区间 。这样,高运动区域会被赋予更大的权重,而低运动区域权重较小。
于是,所有帧的面部感知损失 可定义为:
其中, 和 分别表示目标噪声和预测噪声; 和 对应潜特征的分辨率。
10. SkyReels-A2: Compose Anything in Video Diffusion Transformers Link to 10. SkyReels-A2: Compose Anything in Video Diffusion Transformers
https://arxiv.org/abs/2504.02436
https://github.com/SkyworkAI/SkyReels-A2
将任意视觉元素(例如角色、物体、背景)按照文本提示组合成合成视频
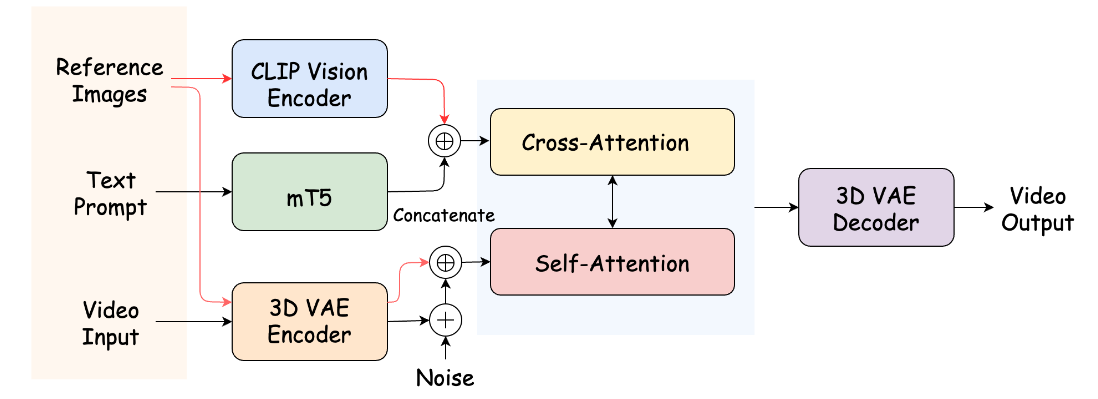
架构 Link to 架构
我们对参考图像中的每个主体进行分割,并将背景单独作为基准参考图像,以避免额外噪声。每个输入参考主体 通过一个双流结构进行跨模态投影。
使用两个不同的分支对所有参考图像进行编码
第一个分支是语义特征分支(用红色顶部箭头表示), CLIP 视觉编码,然后做 MLP 投影,投影模块将这些特征转化为与视频序列查询维度对齐的图像查询。
第二个分支是空间特征分支(用红色底部箭头表示),细粒度的 3D VAE 编码器来处理每个合成图像。参考图像首先在帧维度上拼接,并通过零填充来对齐原始帧数。随后,空间特征沿通道维度与噪声视频 tokens 连接,然后传递到扩散 Transformer 模块中作为key和query,与每个文本提示跨注意力块集成。
训练 Link to 训练
仅优化以下神经模块:跨注意力层、patch embedding、图像条件编码器,而保持其余部分冻结。
推理加速 Link to 推理加速
采用 UniPC 多步调度器 进行推理采样。
采用 Context Parallel、CFG Parallel 和 VAE Parallel 策略来提升模型效率,从而在满足在线环境严格低延迟需求的同时,实现快速且无损的视频生成。
11. MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation Link to 11. MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
数据准备 Link to 数据准备
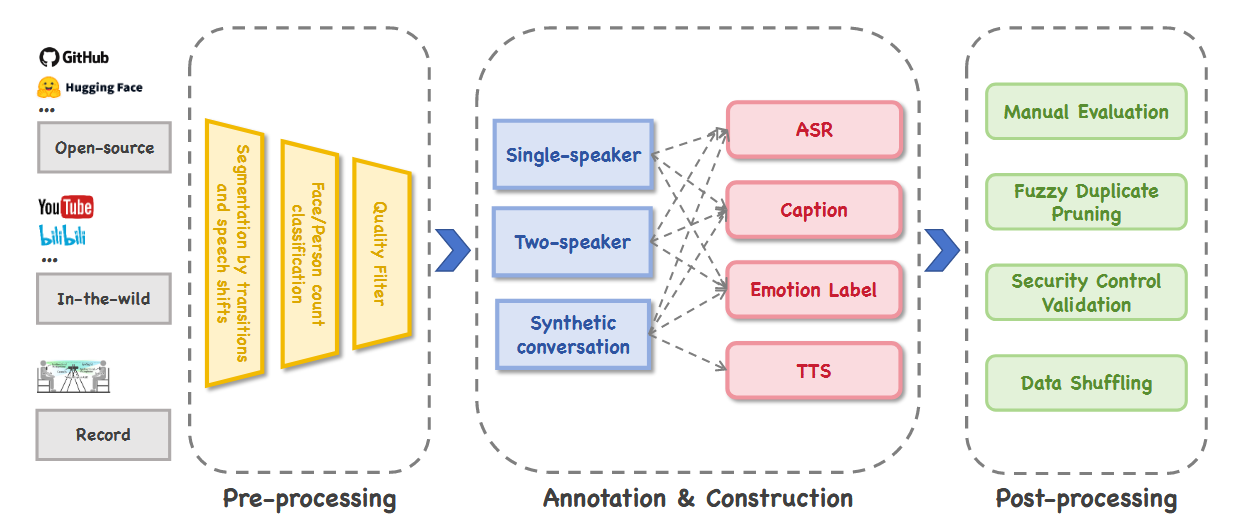
数据处理流程分为三个阶段:
- 预处理:我们采用边界检测和主动说话人检测(ASD)实现时序分割,并利用人脸与人体检测过滤人类主体。每个分割片段需经过视觉质量、音频质量及唇形同步精度的严格评估。
- 标注与合成数据构建:该阶段包括质量评估、字幕生成、情感标注及自动语音识别(ASR)转写。部分单人数据进一步通过语义分析和文本转语音(TTS)合成转化为对话格式。
- 后处理:标注数据结合人工审核与自动抽样,确保子集均衡且高质量。最终数据集包含约 20,000 小时的预训练视频数据和超过 400 小时的监督微调(SFT)数据。
Frame Token表示 Link to Frame Token表示
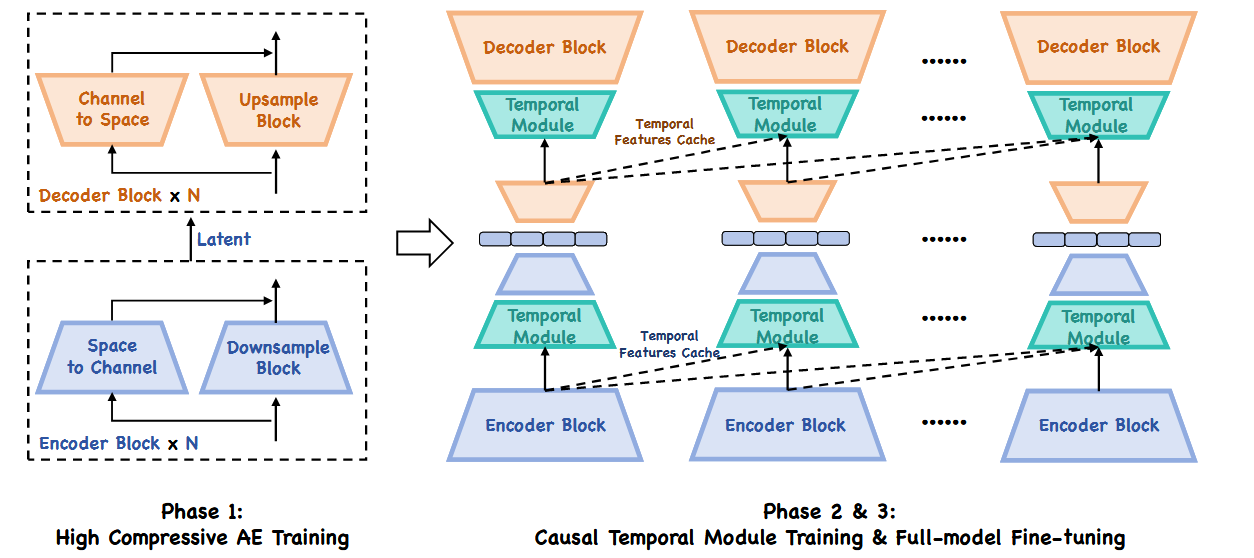
编码要求:
- 在高空间压缩率下保持满意的重建精度,从而支持语言模型主干的高效处理;
- 为支持实时生成,保留时间维度的不压缩。
训练了一个深度压缩自编码器(DC-AE),空间压缩率为 64,通道数为 128,在保证时效性的同时提升时序一致性。
模型学习残差特征,基于空间到通道的变换以实现高效的空间压缩。为了捕捉动态信息,在每个空间卷积层后引入了基于因果的三维卷积层和 RoPE 注意力层。所有时序卷积均采用非对称复制填充。
- 第二阶段:进行时序模块训练。
- 第三阶段:采用 8 帧时序窗口进行全模型微调。
在推理过程中,缓存每帧的时序特征(包括三维卷积输出与 key/value 缓存),并利用 5 帧历史进行逐帧流式编码与解码。
这一流式范式支持实时自回归逐帧生成,同时保证解码中的时序一致性。
尽管更长的历史窗口可能带来更高质量,但 5 帧窗口在计算效率与质量间提供了实用的折中。
Condition表示 Link to Condition表示
- 音频
其中 分别表示音频序列长度和采样率, 分别表示编码后的 token 数和维度。
将每 80ms 音频片段重采样为 16kHz,并使用 Whisper-VQ模块编码,压缩为单个音频 token 表示 ()。
- 姿态
1其中 $K_p, D_p$ 分别表示关键点数量与维度。
用关节速度代替静态关键点表示轨迹,计算方法是相邻帧中对应关节位置的差值。
每帧轨迹通过线性层编码为 个 token,捕捉主要的运动动态。
- 文本
其中 分别表示 chunk 数量和每个 chunk 的长度。
采用预训练的 T5 编码器,将文本条件转化为文本嵌入,token 数 。
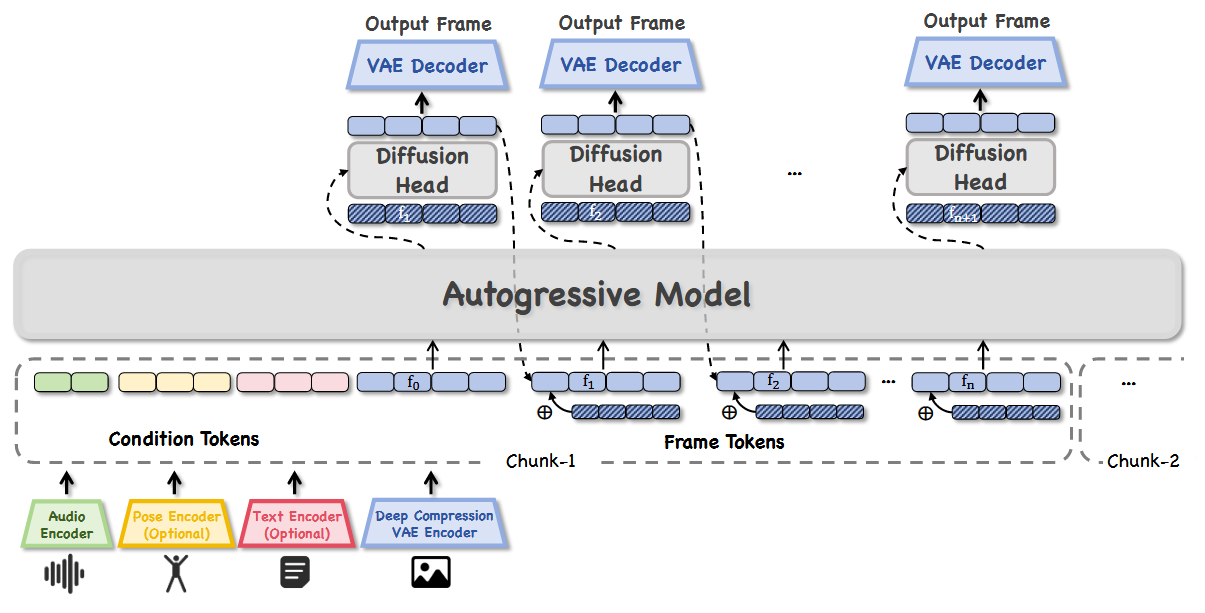
自回归模型 Link to 自回归模型
每个chunk包含对应于 6 帧的一系列多模态 token: 6 个音频 token、60 个姿态 token 和 256 个文本 token 构成,按顺序从左到右拼接。
在这些多模态 token 之后,附加参考图像 token 以及 6 个目标帧的 token(每帧的 token 数由空间分辨率决定)。
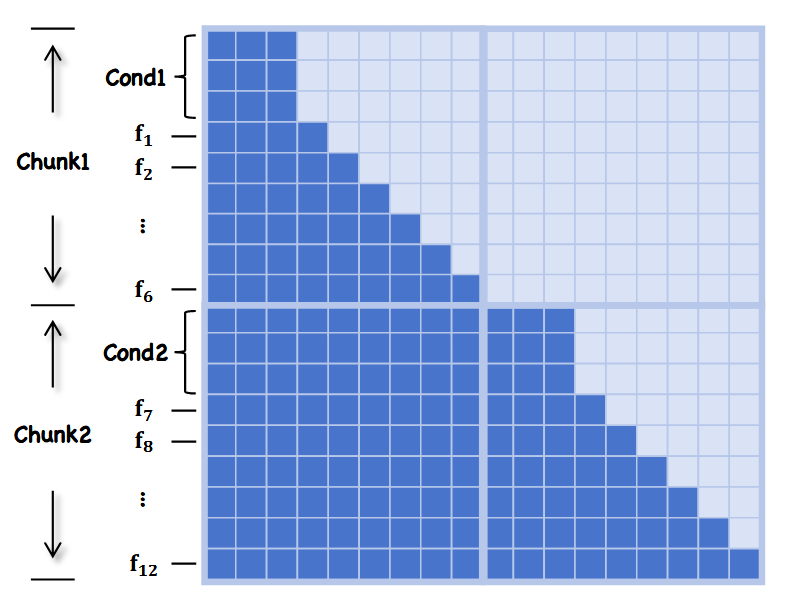
设计了一种专门的帧级因果注意力掩码。在每个chunk内,条件 token 可访问所有后续帧 token,而帧 token 仅能访问条件 token、前序帧 token 及其帧内 token。这种掩码设计同时保证了时序因果性与帧级一致性,为可控的多模态生成提供了可靠机制。
Diffusion Head Link to Diffusion Head
扩散头,将自回归预测结果转化为高质量的视频帧。受 MAR(Li 等, 2024)的启发,将自回归模型的输出作为条件信号注入扩散过程。
但一个关键区别是,完全去除了 mask 建模。由于 LLM 主干已经隐式建模了 token 之间的空间关系和语义一致性,扩散组件只需专注于去噪与渲染干净的帧。