![[图像编辑09] SmartEdit](https://s2.loli.net/2025/03/26/um1qaUOcMZrePWt.png)
Table of Contents
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models Link to SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
From:CVPR2024
Motivation Link to Motivation
现有方法的缺点:
现有模型在复杂场景下的表现效果差
两种情况
- complex understanding scenarios:图中多个物体,但只要求修改其中一个物体的特定属性
- complex reasoning scenarios:编辑的时候,需要额外的“world knowledge”,比如说“移除可以表达时间的物体”,模型不知道什么物体可以表达时间,于是编辑失败
原因为
Diffusion模型中使用的是简单的CLIP Encoder
解决方法是引入MLLM代替CLIP,但仍然有不足,后续会讲继续改进
基于指令的编辑仍然缺少数据,但生成数据又很昂贵
解决方法是提升Unet的感知能力和使用少量高质量场景数据来激发模型能力
Method Link to Method
The Framework of SmartEdit
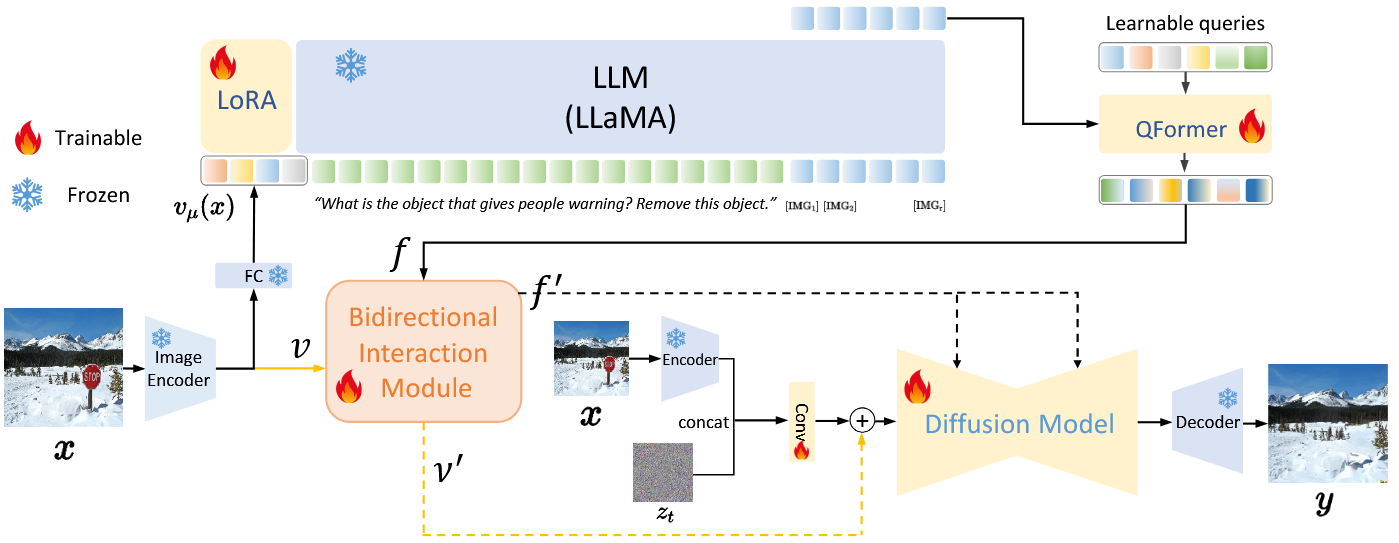
原图经过Image Encoder得到图像特征,再经过层得到
与指令经过tokenize得到的embedding 一起被输入到LLM
LLM的输出是离散的tokens,不能作为后续模块的输入,要转化为hidden state
这里需要讲解一下hidden states和embedding的区别


为了联合optimize LLaVA和Diffusiom model,学习GILL,扩展原先的LLM的词汇,在指令的后面增加个 tokens
确切的说,是将一个trainable的矩阵融入LLM的embedding矩阵
之后,基于先前生成的tokens的条件,minimize这个生成的 tokens的负对数似然
LLM的主要参数被冻结,使用LoRA进行微调,得到hidden states为
考虑到LLM和CLIP的feature spaces的差距,需要把对齐到CLIP的encoder space,使用QFormer得到特征
然后图像特征和经过下一节所说的BIM得到和
以上过程表示为
然后将图像编码后的和噪声潜变量拼接,作为Unet的key和value,通过在输入Unet前通过残差与特征结合
Bidirectional Interaction Module(双向交互模块)
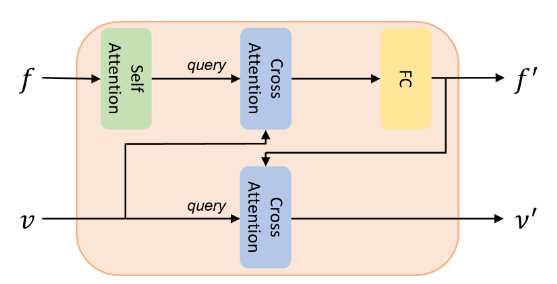
先做self-attention,然后作为query,作为key和value做corss-attention,得到的结果做Pointwise MLP得到
然后作为query,作为key和value,做cross-attention,得到
如此实现文本和图像特征的双重交互
Dataset Utilization Strategy
生成了一些高质量数据来补充数据集,激发MLLM的推理能力
第一个场景方法如下
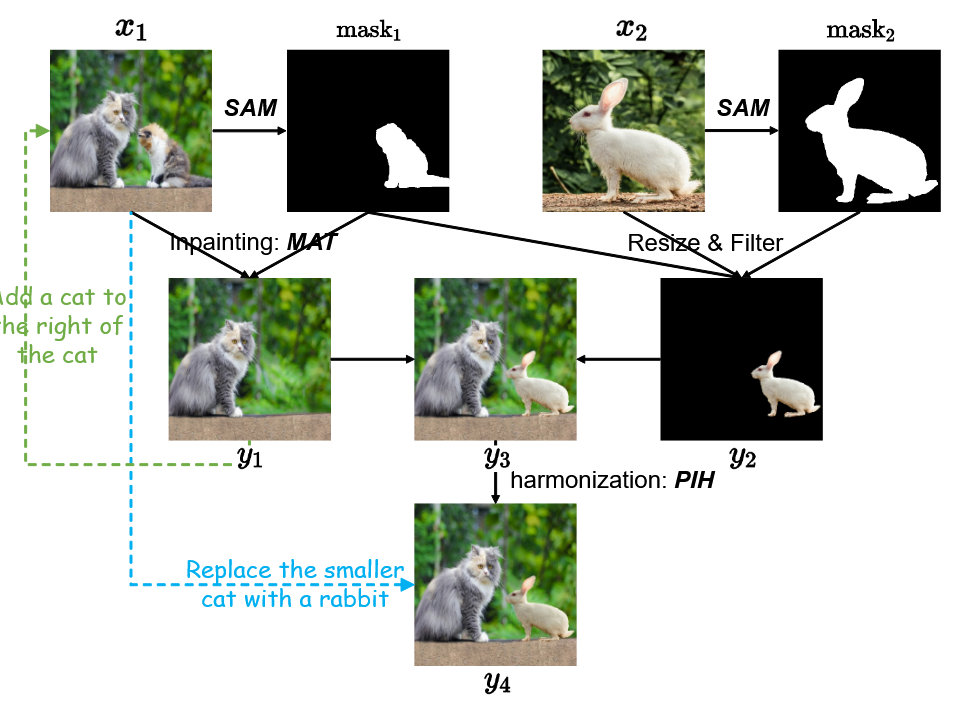
第二个场景说的是,SAM生成物体mask,再用stable diffusion做补全,并人工筛选掉失败的案例,只给了效果图

[图像编辑09] SmartEdit
© JuneSnow | CC BY-SA 4.0