![[图像编辑07] SINE](https://s2.loli.net/2025/03/25/sdrWRjCcFhibvQM.jpg)
Table of Contents
SINE: SINgle Image Editing with Text-to-Image Diffusion Models Link to SINE: SINgle Image Editing with Text-to-Image Diffusion Models
From:CVPR2023
Motivation Link to Motivation
现有的编辑工作有如下缺点:
微调过程会导致预训练的大规模模型在真实图片上过拟合,导致编辑效果不佳
这个说的是用多张图片微调以及使用正则化项,Dreambooth
缺乏对编辑物体的几何结构的合理理解
Method Link to Method
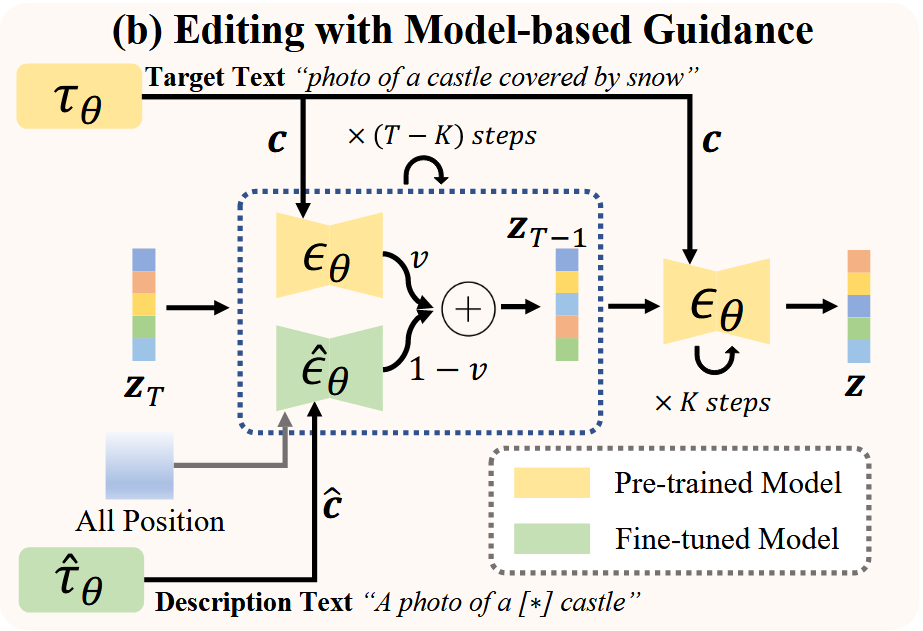
因为直接只使用Fine-tuned Model做生成,会导致过拟合,作者决定融合Fine-tuned Model和Pre-trained Model
之前,class-free guidance的融合文本条件做法是
本文融合的做法是
在这里面,指fine-tuned model,指pre-trained model
并且规定,步只能使用第一个,后面才能再使用第二个公式
关于本文,其实还提出了任意分辨率的图像生成,我没太看得懂,不做细讲
Thanks for reading!
[图像编辑07] SINE
© JuneSnow | CC BY-SA 4.0