![[图像编辑05] Imagic](https://s2.loli.net/2025/03/18/O1F9sPJApuGvmQD.png)
Table of Contents
Imagic: Text-Based Real Image Editing with Diffusion Models Link to Imagic: Text-Based Real Image Editing with Diffusion Models
From: CVPR2023
Motivation Link to Motivation
认为前面的工作有以下问题:
- 仅限于特定类型的编辑,如在图像上涂画、添加物体或转移风格;
- 只能处理特定领域的图像或合成图像(p2p);
- 它们除了输入图像外,还需要辅助输入,例如指示期望编辑位置的图像掩码、相同主题的多张图像,或描述原始图像的文本。
Method Link to Method
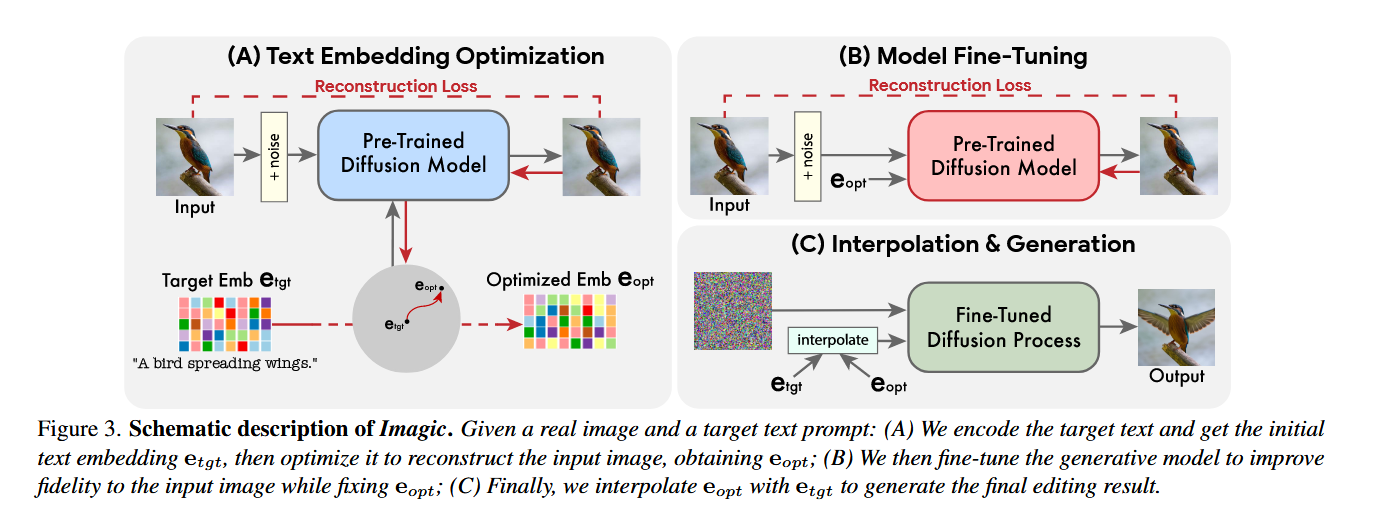
Step1 Text embedding optimization
固定Diffusion model的函数,使用
作为优化函数,对用text encoder编码得到的 做optimize,将optimize得到的叫做使得用
需要满足2点:
- 作为条件去噪得到的图像接近原始输入图像
- 和 这个embedding还要尽可能remain close to
所以这里优化的次数相对较少,原因为
以便保持优化嵌入 接近目标文本嵌入
在邻近空间嵌入向量可以进行线性插值,而远距离的嵌入向量不具备线性行为)
Step2 Diffusion Model fine-tuning
上一阶段获得的优化嵌入 通过扩散模型不一定准确地生成输入图像 ,因为只优化了少量次数
因此,在第二阶段,通过微调扩散模型以使用 获得拟合输入图像
具体做法是,先冻结优化后的嵌入 ,然后使用损失函数来优化扩散模型的参数 ,这里的损失函数和训练Diffusion Model的一样
同时,本文微调了超分模型,使用相同的损失函数 ,但以目标文本嵌入 为条件,因为超分重建是对编辑后的图像进行操作。超分模型的优化能够保留基础分辨率中不存在的高频细节。
Step3 Text embedding interpolation
由于扩散模型被训练为在优化的嵌入 完全重新构建输入图像 ,因此可以使用优化嵌入 沿着在目标文本嵌入 的方向进行需要的编辑
简单来说,Step3就是通过在 和 之间的进行线性插值,从而进行图像编辑。对于给定的超参数 ,插值如下:
以为条件,使用微调后的扩散模型得到低分辨率的编辑图像
然后使用微调的超分模型以目标文本 为条件对其进行超分辨率处理,最终输出高分辨率编辑图像
觉得有点水分,尤其最后一步的线性插值,就插值结合2个嵌入…像是调参大师?
[图像编辑05] Imagic
© JuneSnow | CC BY-SA 4.0