![[图像编辑04] pix2pix-zero](https://s2.loli.net/2025/03/18/C9LUe7nGrOpRSsY.jpg)
Table of Contents
Zero-shot Image-to-Image Translation Link to Zero-shot Image-to-Image Translation
From: SIGGRAPH2023
Motivation Link to Motivation
有以下3个Motivation:
- 图像本身并不自然地带有文本描述。指定一个文本描述既繁琐又耗时,因为图像的纹理、光照、形状等信息过于复杂,难以准确描述;
- 类似于p2p提出的,prompt轻微改动,生成的图片改动很大;
- 用户要编辑大量的图片,所以我们不能为每一种编辑类型和每一张图片做单独的微调。
Method Link to Method
Inverting Real Images
Deterministic inversion
反演是说,要把原图变成一个噪声图,然后可以在采样的时候把重建为。
因为DDPM的forward和reverse过程都是随机的,而DDIM则可以设置来保证reverse过程的确定性,所以使用DDIM的reverse过程。具体的讲解请移步[图像编辑外传01] DDIM Inversion。
Noise regularization
第一步Inversion得到的不满足高斯白噪声,所以作者又做了一个噪声正则化。
下面的内容纯翻译了。。。我真的看不懂
作者遵循Analyzing and Improving the Image Quality of StyleGAN的方法,构建一个金字塔,其中初始噪声水平 是预测的噪声图,每个后续噪声图通过 2x2 的领域平均池化(并乘以 2 以保持期望的方差)。作者在特征图大小 8x8 处停止,创建 4 个噪声图,形成集合 。
在金字塔级别 的成对正则化是可能的 偏移处自相关系数平方和,归一化过噪声图大小 :
其中, 在使用圆形索引和通道的空间位置中索引。
总目标函数为
Discovering Edit Directions
编辑方法是提供一个方向,比如”cat -> dog”
那么就需要设计一个方法,来计算text embedding direction vector
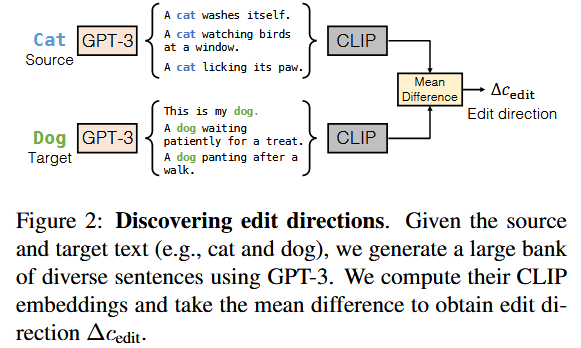
如图所示,使用GPT-3根据”cat”和”dog”生成大量且多样的句子,计算CLIP embedding,根据平均差距得到编辑方向
然后就可以使用生成编辑后的图片
Editing via Cross-Attention Guidance
其实prompt to prompt早已提出cross-attention的attention map与图像结构有紧密联系
如果直接使用生成的话,图像结构会有很大变化,如下图最后一排所示

作者这里使用一个两步的方法完成图像结构的控制
Step1

对每个时间步t,只使用,获得每个时间步t的cross-attention的
再对于每个时间步t,使用,获得每个时间步t的cross-attention的
Step2
使用
来约束attention-map的偏差
其实我是有点不理解的。。。你这样一约束不就全部一样了?(xor)暂且先搁置这个问题吧
[图像编辑04] pix2pix-zero
© JuneSnow | CC BY-SA 4.0