![[图像编辑02] DiffEdit](https://s2.loli.net/2025/03/18/kKApDQ2IzGYyVvH.jpg)
Table of Contents
DiffEdit: Diffusion-based semantic image editing with mask guidance Link to DiffEdit: Diffusion-based semantic image editing with mask guidance
From: ICLR2023
Motivation Link to Motivation
之前的工作存在的问题:
编辑时忽略了输入图像的部分信息;(例如:将狗更改为猫,不应该修改动物的颜色和姿势—>风格一致性);
必须提供mask作为输入,以告诉扩散模型应该编辑图像的哪些部分。
Method Link to Method
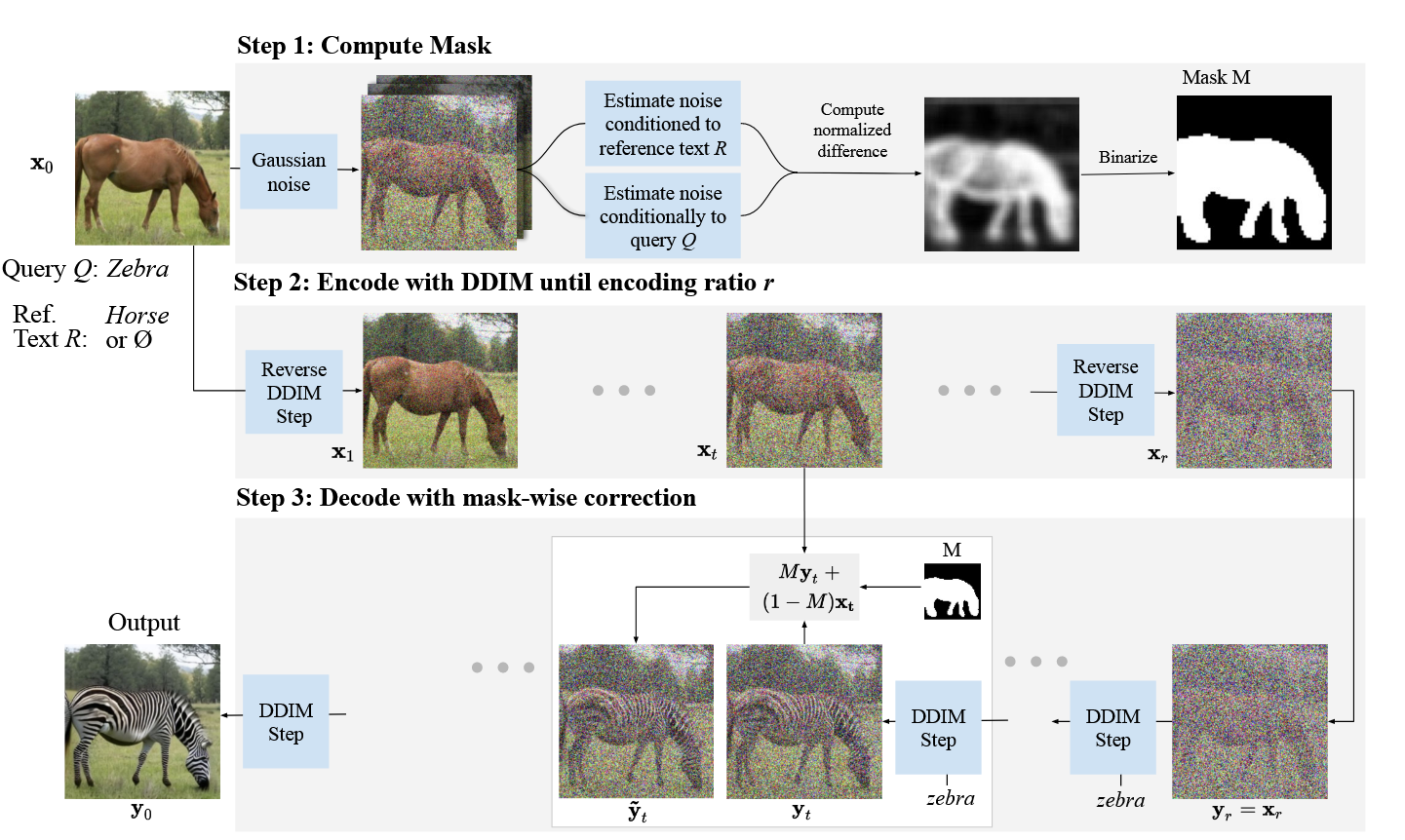
Step1:Computing editing mask
Denoise一张image的时候,Text-conditioned Diffusion Model会根据给定文本条件的不同,生成不同的noise estimates(噪声估计)。作者认为estimates的结果哪里是不同的,就代表了那块区域的不同是文本不同引起的,由此找到mask区域。
如上图的Step1步骤,用reference text 和query 或 做噪声估计就会在动物的身体部分产生差异。这一点还不足以确定就是这块区域,作者还更严谨的提出,对于背景,noise estimates的结果几乎没有差异,因为推断可以使用该方法找到要编辑的mask区域。
Step2:Encoding
用DDIM的Encoder,使用步,在隐空间编码输入的原图为
这一步使用的使用的是unconditional model,也就是使用条件文本为
Step3: Decoding with mask guidance
基于文本条件Query 和Mask ,使用DDIM decode隐变量到
对于mask 之外的区域,为了保证和原图一致。使用的那片以外区域的像素值直接替换
Mask-guided DDIM被更新重写为,而的计算方法还是DDIM那一套,就是之前DDIM encoder得到的那个隐变量
为什么要在 DDIM 编码后再解码?因为普通的去噪过程是根据纯噪声+条件执行反向去噪过程,这个过程是随机的。而 DDIM 编码后解码的过程在 mask 区域以外是具有确定性的,如果没有额外因素,最后便会复原回原先的背景。(关于DDIM的反向过程的确定性其实在后续任务做Inversion的时候也提到了,可以再看后续的我写的文章)
关于
越大,越遵循text query的编辑,但与原图偏离越远。
[图像编辑02] DiffEdit
© JuneSnow | CC BY-SA 4.0